
Google DeepMindは2026年6月3日、オープンウェイトモデル「Gemma 4」に12B Unifiedを追加した。単なる中間サイズの追加ではない。4月に出たGemma 4はE2B、E4B、26B A4B MoE、31B Denseで構成され、端末向けの小型モデルとワークステーション以上を想定した大型モデルの間に空白があった。今回の12B Unifiedは、その空白を埋めると同時に、音声と画像を別体のエンコーダーへ逃がさず、単一のLLMバックボーンに直接流す設計を前面に出したモデルである。
Googleは、Gemma 4 12Bを「ラップトップへエージェント的なマルチモーダル知能を持ち込む」モデルと位置付けている。配布はApache 2.0ライセンスのオープンウェイトで、事前学習版とinstruction-tuned版がHugging FaceとKaggleから入手できる。対象はクラウドAPIだけではなく、LM Studio、Ollama、llama.cpp、MLX、vLLM、SGLang、Unsloth、LiteRT-LM、Google AI Edge Galleryなどを含むローカル実行の開発者環境だ。Googleは16GB VRAMまたはユニファイドメモリを備えた専用GPUラップトップでのローカル実行を打ち出しており、モデルの価値は「高性能な公開モデル」よりも「音声・画像・テキストを扱うローカルエージェントの実装面」にある。
12B UnifiedはGemma 4の隙間を埋めるモデルだ
Gemma 4の既存ラインアップでは、E2BとE4Bがモバイルやエッジ向け、26B A4B MoEが高速推論重視、31B Denseが品質とファインチューニングの土台という役割を持っていた。モデルカード上では、E2BとE4Bはテキスト、画像、音声を扱える一方、26B A4Bと31B Denseはテキストと画像に限られる。12B Unifiedは11.95Bパラメータ、48層、1024トークンのスライディングウィンドウ、256Kトークンのコンテキスト長、262K語彙を持ち、対応モダリティはテキスト、画像、音声である。
この配置が効いてくるのは、ローカルで動くエージェントに音声や視覚入力を渡したい場合だ。E2B/E4Bは端末向けの軽量性が強いが、複雑な推論やコード生成では余力が限られる。26B/31Bは性能の軸では上位だが、音声入力をネイティブに持たない。12B Unifiedは、その中間で音声入力を持つ最初の中規模Gemmaとして出てきた。Googleが「E4Bと26B MoEの間を橋渡しする」と説明する理由は、パラメータ数の中間というより、入出力の現実性と推論能力の折り合いにある。
Gemma 4 12Bの発表時点で、GoogleはGemma 4モデルのダウンロード数が1億5000万回を超えたとしている。4月のGemma 4発表では、Gemma全体で4億回超のダウンロードと10万超の派生モデルが示されていた。公開モデルの競争では、モデル単体のベンチマークだけでなく、周辺の実行環境、派生モデル、ローカル運用ノウハウが広がる速度が導入判断に効く。12B Unifiedは、そのエコシステムに「中規模の音声・画像対応」という欠けていた型を足した。
エンコーダーを外したことは、メモリとチューニングの問題に直結する
Gemma 4 12Bの技術的な差分は、マルチモーダル入力を処理する別体エンコーダーをなくした点にある。従来のマルチモーダルモデルでは、画像や音声を専用エンコーダーで表現へ変換し、その結果をLLMへ渡す構成が一般的だった。Googleの開発者向け解説によると、Gemma 4の他の中規模モデルでは約5億5000万パラメータのビジョンモデルが使われ、E2B/E4Bの音声処理では約3億パラメータの音声エンコーダーと12層のconformerが関わっていた。
12B Unifiedでは、画像側は35Mパラメータの軽量なvision embedderに置き換えられる。生の48×48ピクセルパッチを単一の行列積でLLMの隠れ次元へ射影し、X/Yの座標ルックアップで位置情報を加える。音声側はさらに直接的で、16kHzの音声を40ミリ秒ごとのフレームに切り、640個のfloatをLLM入力空間へ線形射影する。Googleはこれを、音声・画像・テキストが同じ重みを共有する「単一のdecoder-only transformer」として説明している。
この設計は、単に部品点数を減らす話ではない。別体エンコーダーがあると、推論時のメモリフットプリントとレイテンシが増え、ファインチューニング時にもLLM本体とエンコーダーの境界を意識する必要が出る。12B Unifiedでは、LoRAのようなアダプター調整やフルチューニングで、マルチモーダル入力の流れを一つのループとして扱いやすくなる。これは、ローカルで音声エージェントや画面理解エージェントを作る開発者にとって、モデルの賢さとは別の実装上の価値である。
ただし、エンコーダーを外したことがすべての用途で優位という意味ではない。専用エンコーダーは、特定モダリティで効率的な特徴抽出を行うために使われてきた。12B Unifiedの価値は、画像・音声・テキストを同じモデル内で扱う統合性と、ローカル推論に向けたメモリ構造の単純化にある。専門用途での精度や長時間音声の扱いは、実装環境とタスクごとの検証に残る。
ベンチマーク性能は26Bに近いが、万能の同等性ではない
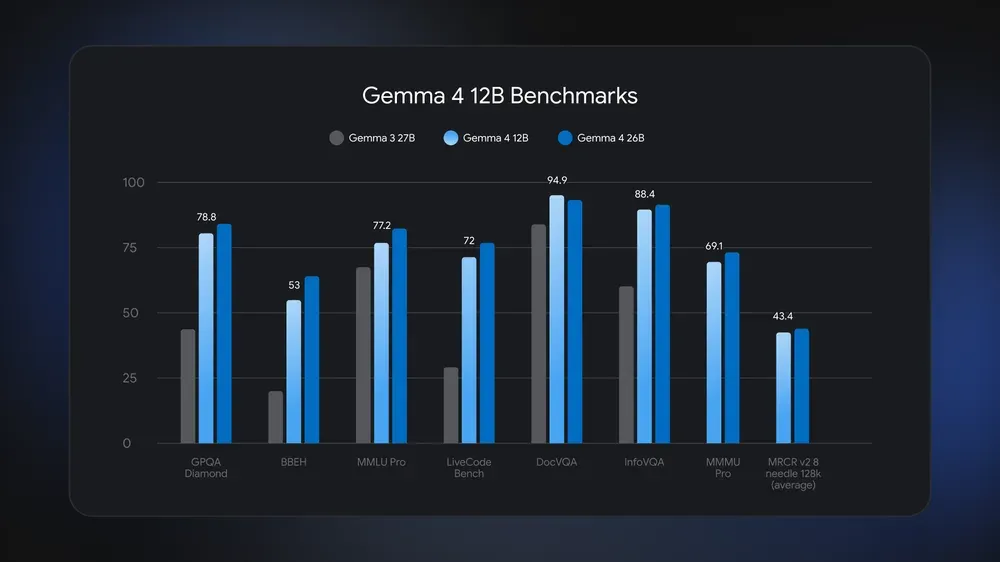
GoogleはGemma 4 12Bについて、標準ベンチマークで26B MoEに近い性能を示すと説明している。モデルカードの数値を見ると、その表現には幅がある。instruction-tunedモデルのMMLU Proは12B Unifiedが77.2%、26B A4Bが82.6%。LiveCodeBench v6は12Bが72.0%、26Bが77.1%。GPQA Diamondは12Bが78.8%、26Bが82.3%で、複数の指標では確かに大きく離れていない。
一方で、AIME 2026 no toolsでは12Bが77.5%、26Bが88.3%で、数学系の難問では差が出ている。BigBench Extra Hardも12Bが53.0%、26Bが64.8%だ。長文探索のMRCR v2 8 needle 128kは12Bが43.4%、26Bが44.1%で近いが、31B Denseの66.4%には届かない。視覚系ではMMMU Proが12Bで69.1%、26Bで73.8%、MATH-Visionが12Bで79.7%、26Bで82.4%となっている。
この数字から読めるのは、12B Unifiedが26Bを置き換えるというより、音声対応とローカル運用を含めた総合設計で別の場所を取りに来たということだ。Tau2の平均では12Bが69.0%、26Bが68.2%とわずかに上回る一方、AIMEやBigBench Extra Hardでは差が残る。Googleの「26Bに近い」という表現は、選択したベンチマークの範囲では成立するが、すべての推論タスクで同等と読むべきではない。
音声の評価では、12B UnifiedにCoVoST 38.5、FLEURS 0.069という数値が示されている。E4BはCoVoST 35.54、FLEURS 0.08、E2BはCoVoST 33.47、FLEURS 0.09で、音声対応モデルの中では12Bが上に置かれる。ここでも焦点は、大型テキストモデルとの純粋な競争ではなく、音声をネイティブに取り込むローカルモデルとして、どこまで実用的な推論と応答速度を両立できるかにある。
リリースは重みだけでなく、ローカル実行の導線まで含んでいる
Gemma 4 12Bの発表で目立つのは、モデルの配布先よりも、動かし方の導線が細かく用意されている点だ。GoogleはLM Studio、Ollama、Google AI Edge Gallery、Google AI Edge Eloquent、LiteRT-LM CLIを試用先として挙げ、Hugging Face Transformers、llama.cpp、MLX、SGLang、vLLM、Unslothでの推論やチューニングにも触れている。クラウド側では、発表文がリンク先として示すGemini Enterprise Agent Platform Model Gardenのほか、Cloud Run、GKEでのデプロイも案内している。
開発者向けガイドでは、macOS向けのGoogle AI Edge Galleryデスクトップ体験と、Google AI Edge Eloquent on MacにおけるVoice Editの会話入力サポートが示された。LiteRT-LMでは、litert-lm serveによってローカルのOpenAI互換APIサーバーとしてGemma 4 12Bを動かせるとされる。Continue、Aider、OpenClaw、Hermes、OpenCodeのような既存のエージェント/開発ツールから呼び出せる構成にすれば、モデルの置き換えは「新しいSDKを覚える」よりも「ローカルAPIエンドポイントを差す」に近づく。
Multi-Token Prediction(MTP)drafterも、12B Unifiedの実用面を支える要素だ。Googleは5月に、Gemma 4向けのMTP drafterで、speculative decodingにより最大3倍の高速化をうたっていた。12B UnifiedもMTP drafterを備え、重いターゲットモデルの出力候補を軽量なdrafterが先読みし、ターゲット側が並列に検証する構成を取る。ローカル音声アプリやコーディングエージェントでは、品質だけでなく応答の待ち時間が体験を決めるため、この高速化の実効値は採用判断の中心になる。
ただし、MTPの効果はランタイム、量子化、バッチサイズ、ハードウェアによって変わる。GoogleのMTP解説でも、Apple Silicon上の26B MoEではバッチサイズ1のルーティングに固有の難しさがあり、複数リクエストをまとめると速度向上が開くと説明されていた。12B Unifiedでも、16GB級のローカル環境でどの量子化を使うか、音声と画像を同時に入れた時にどの程度のレイテンシになるかは、ベンチマーク表だけでは決まらない。
制約は短い入力窓と実機条件に残る
Gemma 4 12Bはマルチモーダル対応を前面に出すが、モデルカード上の音声と動画の制約ははっきりしている。音声入力の最大長は30秒。動画はフレーム列として処理できるが、1秒1フレームを前提に最大60秒である。これは会議全体の逐次理解や、長時間ストリーミング音声をそのまま処理するモデルではないことを意味する。実用時には、音声区間を切り出し、必要なら外部のストリーミング処理やメモリ管理と組み合わせる必要がある。
画像側にも計算量との交換条件がある。Gemma 4は可変解像度に対応し、画像の表現に使うvisual token budgetを70、140、280、560、1120から選べる。分類やキャプション、動画フレーム処理では低い予算で速度を優先し、OCRや文書解析、小さな文字を読む用途では高い予算を使う。つまり、12B Unifiedがローカルで動くとしても、どの入力をどれだけ細かく見るかはアプリ側の設計問題として残る。
それでも、今回の追加はGemma 4の用途をかなり具体的に広げる。音声で指示し、画面や画像を見せ、ローカルでコードを書かせるようなエージェントは、クラウド大規模モデルだけでなく、手元のマシン上で閉じた構成でも試しやすくなる。プライバシー、オフライン性、低遅延、コスト管理を優先する開発者にとって、12B Unifiedは「小さくて軽い」だけの端末モデルとは別の選択肢だ。
Googleにとっても、このモデルはGemini APIと競合するというより、Gemmaの裾野をローカルエージェントへ寄せる役割を持つ。大規模な推論、最新知識、長時間メディア処理ではクラウドモデルが残る。一方で、短い音声、画像、UI、コード、ローカルツール呼び出しを扱う反復的なワークフローでは、12B Unifiedのような中規模公開モデルが開発の初期探索を速くする。次の焦点は、Googleが示した16GB級の動作条件が、実際の量子化モデル、MTP、ローカルAPIサーバー、音声・画像混在入力の組み合わせでどこまで安定するかである。


