
著名なハードウェアリーカーであるKepler_L2によって提示された次世代GPUのブロック図が、業界で大きな注目を集めている。AMD内部からのリークとされるこの情報がAMDの次世代アーキテクチャ「UDNA」(通称RDNA 5)を示しているのならば、同社はGPU市場における戦略を根本から覆し、再びハイエンド性能の頂点を目指す野心的な計画を推進していることになる。96コンピュートユニット(CU)を搭載するフラッグシップダイの存在、そして市場のあらゆるセグメントを網羅する4つの異なるダイ構成は、アーキテクチャ思想の統合と市場戦略の再定義を示していると言えるだろう。
ハイエンド市場への帰還:なぜAMDはUDNAで勝負をかけるのか
AMDの近年のGPU戦略を理解するには、RDNA 4世代での意図的な「不在」を振り返る必要がある。同社はRDNA 4アーキテクチャにおいて、ハイエンド市場、すなわちNVIDIAの最上位モデルと直接競合する製品の投入を見送り、性能と電力効率に優れたミドルレンジ市場にリソースを集中させた。これは、限られた開発リソースを最も収益性の高いセグメントに投入するという、現実的かつ合理的な経営判断であった。しかし、この戦略は同時に、最高性能を求めるエンスージアスト層や、AI開発の最前線で要求される圧倒的な演算能力において、NVIDIAに主導権を明け渡すことを意味した。
UDNA(Unified DNA)という名称が暗示するように、この新アーキテクチャの最大の目標は、これまでゲーミング向けに最適化されてきた「RDNA」と、データセンターやHPC(ハイパフォーマンスコンピューティング)向けに設計されてきた「CDNA」という二つの系譜を統合することにある。この統合は、現代のコンピューティング環境における必然的な帰結である。今日の最先端ゲームは、リアルタイムレイトレーシングやAIを活用したアップスケーリング、物理シミュレーションなど、膨大な並列演算を要求し、その性質はHPCアプリケーションに近づきつつある。一方で、コンシューマ向けGPUで培われたグラフィックスパイプラインやメディアエンジンは、プロフェッショナルなクリエイティブワークやAIのデータ可視化においても重要性を増している。
単一の、スケーラブルなアーキテクチャを設計し、それをゲーミングからデータセンターまで展開することは、開発効率を最大化し、ソフトウェアエコシステムを統一する上で極めて合理的だ。NVIDIAがGeForceとデータセンター向けGPUでCUDAという統一プラットフォームを築き上げたように、AMDもまた、UDNAによってRadeonとInstinctを同じ基盤の上に立たせようとしている。そして、この壮大な統合戦略を成功させるためには、アーキテクチャの頂点に君臨する「フラッグシップ」の存在が不可欠となる。96 CUという構成は、単にゲームで高いフレームレートを出すためだけでなく、AIワークロードにおいてもNVIDIAと渡り合うための、AMDの明確な意思表示と見るべきだろう。
Kepler_L2が示す4つのダイ構成を徹底分析
今回、Kepler_L2によって提示されたブロック図は、AT0、AT2、AT3、AT4と仮称される4つの異なるダイ構成を示している。これらの図は、AMDがUDNAアーキテクチャを極めてモジュール性の高い設計思想で構築していることを物語っている。
AT0: 96 CUフラッグシップ・ダイの構造と性能予測
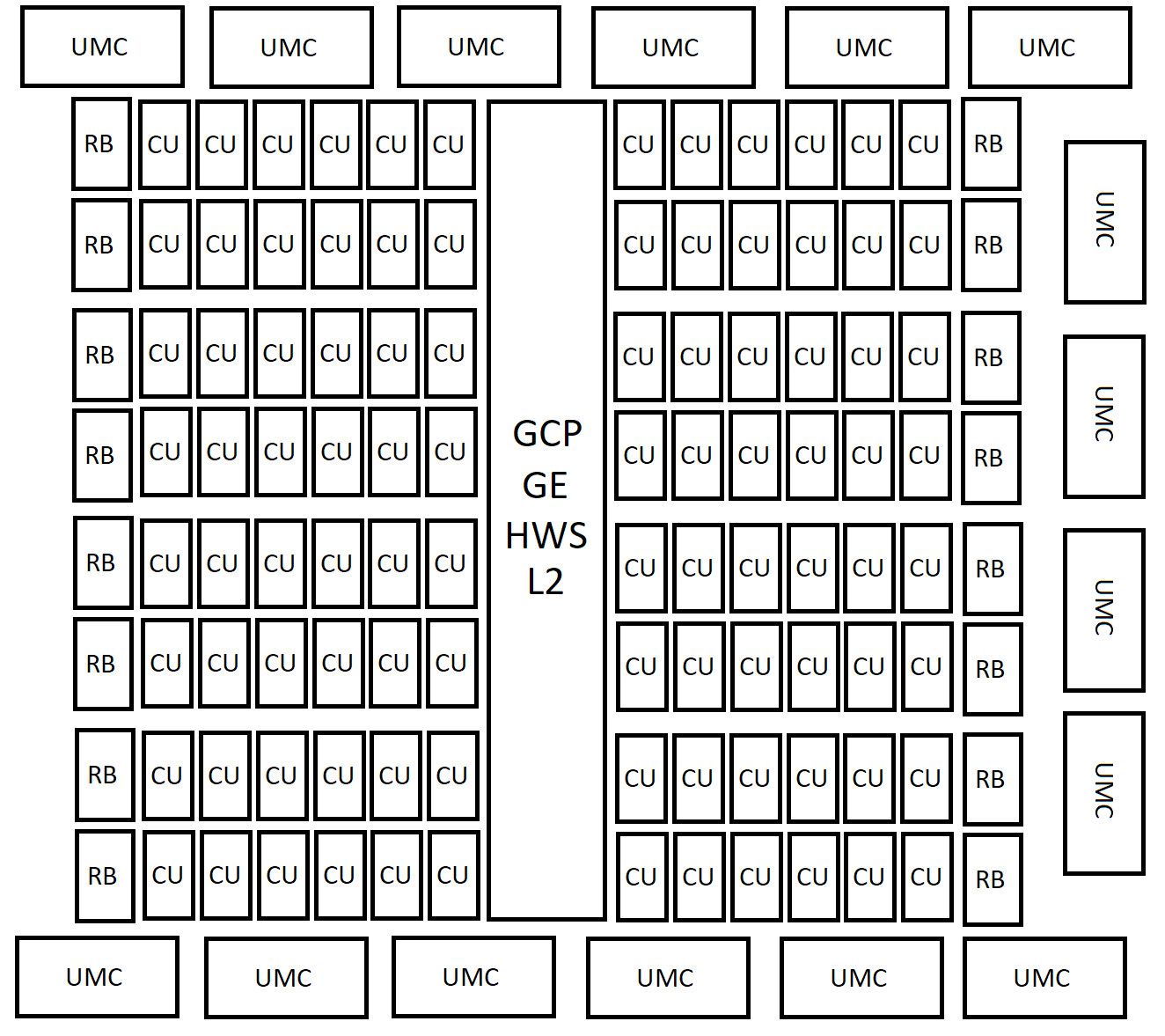
最も注目すべきは、紛れもなく最上位の「AT0」ダイだ。その構成は、AMDがハイエンドGPUの設計思想を根本から見直していることを示唆している。
- 階層構造: ブロック図によれば、AT0は8基の「シェーダーアレイ(SA)」で構成され、各SAは2基の「シェーダーエンジン(SE)」を内包する。そして、各SEが6基の「コンピュートユニット(CU)」を持つ。これにより、
8 SA * 2 SE/SA * 6 CU/SE = 96 CUという計算が成り立つ。これは、RDNA 4の最上位とされるNavi 48の64 CUから実に50%もの増加であり、単純計算でも大幅な性能向上が期待される。 - メモリサブシステム: さらに重要なのがメモリインターフェースだ。図には16基の「ユニファイドメモリコントローラ(UMC)」が描かれている。各UMCが32-bit幅のインターフェースを持つと仮定すれば、合計で512-bitという広大なメモリバス幅が実現する。これは、AMDがRDNA 3(最大384-bit)で採用したチップレット構造とは異なる、モノリシックな超広帯域インターフェースへの回帰を示唆している。GDDR7メモリと組み合わせることで、そのメモリ帯域は2.0TB/sを超える可能性があり、これは4K以上の高解像度ゲーミングや大規模なAIモデルの学習において決定的なアドバンテージとなる。
- CUの再定義: ここで一つの重要な仮説が浮上する。それは「1 UDNA CU = 1 RDNA 4 WGP(Workgroup Processor)」という説だ。RDNA 4において、WGPは実質的に2つのCUをペアにした演算単位として機能していた。もしこの説が正しければ、UDNAの96 CUは、従来のRDNAアーキテクチャで言うところの192 CUに相当する演算リソースを持つことになる。これは、シェーダーコアの数だけでなく、命令発行ポートやスケジューラの構造も大きく変更されることを意味し、ALU(演算器)の密度と稼働率を飛躍的に向上させる設計思想の転換と考えられる。この変更は、NVIDIAがAmpereアーキテクチャ(RTX 30シリーズ)でCUDAコアの定義を変更し、FP32演算能力を倍増させた戦略と軌を一にするものだ。
このAT0ダイを搭載した製品は、間違いなくNVIDIAの次世代フラッグシップ(RTX 5090やその後継)に直接対抗するために設計されている。AMDが長らく不在だった「絶対性能」の王座に、再び本気で挑むための切り札である。
AT2: 40 CUミドルレンジ・ダイ – 次世代のスイートスポットか
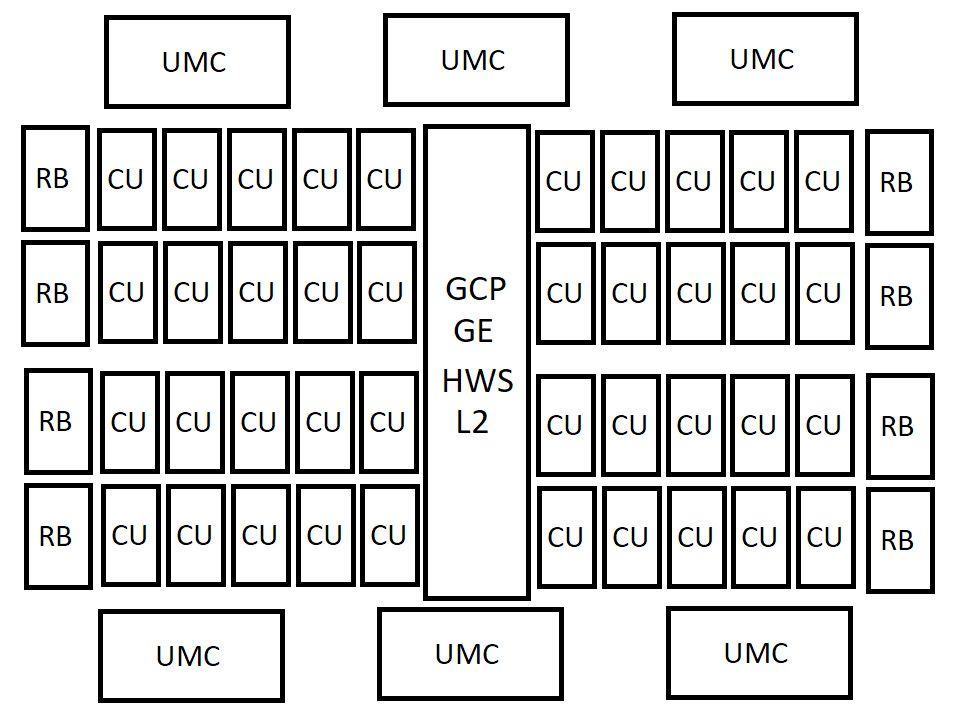
AT0がエンスージアスト向けのフラッグシップである一方、「AT2」はより広範な市場を狙うミドルレンジからハイエンドにかけての主力となるダイだと考えられる。
- 構成: 4基のシェーダーアレイ、8基のシェーダーエンジン、そして合計40 CUという構成を持つ。各SEが5 CUを持つという、AT0とは異なる非対称な構成が興味深い。これは、ダイサイズと性能のバランスを最適化するための設計上の判断だろう。
- メモリバス: 6基のUMCが描かれており、これは192-bitのメモリバスを示唆している。現行世代で言えば、Radeon RX 7800 XT(256-bit)とRX 7700 XT(192-bit)の中間に位置するが、GDDR7メモリの採用により、バス幅が狭くても実効帯域はRDNA 3世代のミドルレンジ製品を上回る可能性が高い。
- 市場での位置づけ: この40 CUダイは、次世代における「スイートスポット」となる可能性を秘めている。TSMCの先進的な3nmクラスのプロセス(N3Eなど)で製造されると仮定すれば、優れた電力効率を実現できるはずだ。RDNA 4世代の主力であるNavi 48(64 CU)と比較してCU数は少ないものの、前述したCUの再定義やアーキテクチャ全体の効率改善により、同等以上のゲーミング性能をより低い消費電力で実現することが目標となるだろう。
AT3 & AT4: ローエンド市場と新たなメモリ戦略
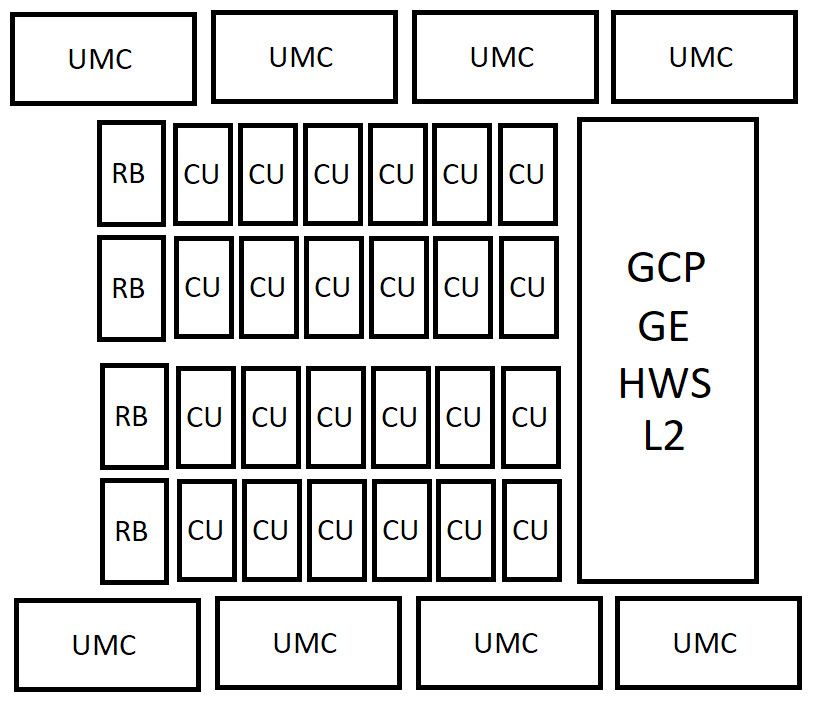
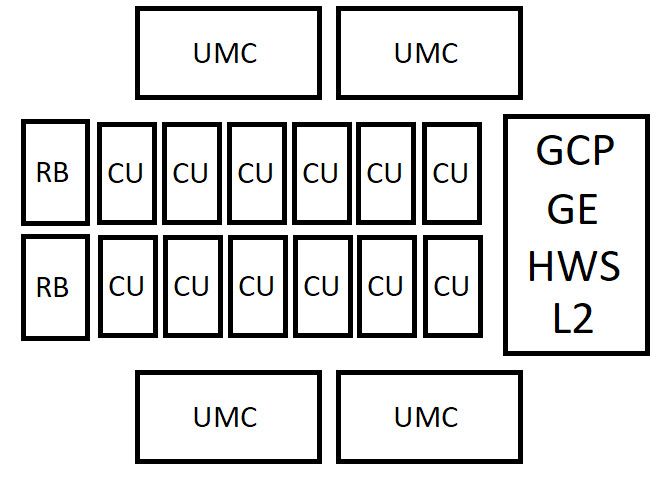
「AT3」(24 CU)と「AT4」(12 CU)は、エントリーレベルのディスクリートGPU、モバイル向けGPU、そして次世代APUへの統合を視野に入れた設計と見られる。
- 構成の奇妙さ: ここで興味深いのは、AT3(24 CU)が8基のUMC(最大256-bit)を持つのに対し、より上位のAT2(40 CU)が6基のUMC(192-bit)しか持たないという逆転現象だ。これは、単なるディスクリートGPUとしての設計思想だけでは説明が難しい。
- LPDDRメモリ採用の可能性: この謎を解く鍵は、一部で噂されているLPDDR(Low-Power DDR)メモリの採用にある。GDDRメモリが高帯域だが高コスト・高消費電力であるのに対し、スマートフォンやノートPCで広く使われるLPDDRメモリは、より安価で消費電力が低く、より広いバス幅を実装しやすいという特徴がある。AT3やAT4のようなローエンド製品でLPDDR5Xや次世代のLPDDR6を採用することで、製造コストを抑えつつ、GDDRメモリよりも大容量のVRAM(例: 12GBや16GB)をエントリークラスの製品に搭載することが可能になる。
- アーキテクチャへの影響: もちろん、LPDDRはGDDRに比べてピーク帯域で劣る。このハンデキャップを克服するためには、大規模なオンダイキャッシュが不可欠だ。CDNAアーキテクチャとの統合により、CUあたりのローカルキャッシュ(LDS: Local Data Share)が大幅に増強され、さらにInfinity Cacheを組み合わせることで、メモリ帯域への要求を緩和する設計が考えられる。これは、メモリサブシステムにおけるコストと性能のトレードオフを再定義する、野心的な試みと言えるだろう。
アーキテクチャの進化点:UDNAはRDNA 4から何を変えるのか
UDNAは単なるCU数の増加に留まらず、アーキテクチャの根幹にメスを入れる大規模な刷新となる可能性が高い。
メモリ階層の再構築とInfinity Cacheの役割変化
RDNA 2で導入されたInfinity Cacheは、比較的狭いメモリバス幅の弱点を補い、実効帯域を向上させる画期的な技術だった。しかし、大規模なSRAMキャッシュはダイサイズを圧迫し、コスト増の要因ともなる。
UDNAでは、CDNAアーキテクチャの思想が取り入れられることで、メモリ階層全体が再設計されると予測される。特に、データセンター向けGPU「Instinct MI400」で採用される次世代CDNAアーキテクチャでは、CUあたりの共有L0/LDSキャッシュが大幅に増加すると言われている。この流れがUDNAにも適用されれば、GPU内部でのデータ再利用率が劇的に向上し、Infinity Cacheや外部メモリへのアクセス頻度を低減できる。
これは、Infinity Cacheへの依存度を下げ、よりバランスの取れたメモリ階層を構築しようとする意図の現れかもしれない。レイテンシを重視するワークロード(ゲーミング)と、帯域を重視するワークロード(AI学習)の両方で高い性能を発揮するには、このような柔軟なメモリ階層の設計が不可欠である。
レイトレーシング性能の抜本的改善への道筋
これまでAMD RDNAアーキテクチャの課題とされてきたのが、NVIDIAのRTコアに比肩するレイトレーシング性能の実現だった。UDNAでは、この分野での抜本的な改善が必須となる。
アーキテクチャレベルでの改善策としては、以下の点が考えられる。
- BVH(Bounding Volume Hierarchy)アクセラレーションの強化: レイトレーシングの中核となるBVHトラバーサル処理を専門に行うハードウェアユニットの性能向上。より複雑なシーン構造を効率的に処理するための命令セットの追加や、内部パイプラインの最適化。
- スレッドスケジューリングの最適化: レイトレーシングは、光線がオブジェクトに衝突するたびに処理が分岐し、実行スレッドが非効率な状態(Divergence)に陥りやすい。このスレッドの発散をハードウェアレベルで効率的に再編成し、シェーダーコアの稼働率を維持する仕組みの導入。これは、NVIDIAが長年のGPUアーキテクチャ開発で培ってきたノウハウであり、AMDが追いつくべき最重要課題の一つである。
- AIによるデノイズ技術の連携強化: レイトレーシングのレンダリング結果からノイズを除去するデノイザは、最終的な画質を決定する重要な要素だ。UDNAのAI性能向上は、より高度で高速なAIデノイザの実装を可能にし、少ない光線数でも高品質な画像を生成することに貢献するだろう。
これらの改善が実現すれば、AMDは長年の課題を克服し、リアルタイムレイトレーシングにおいてもNVIDIAと互角に戦える土壌を整えることができる。
2026年のGPU戦争を占う
リーク情報によれば、AMDの次世代ゲーミングGPUは2026年第2四半期に量産開始が予定されている。このタイミングは、次世代のGPU市場の勢力図を大きく左右する重要な時期となる。
熾烈化する次世代GPU競争
2026年初頭から中盤にかけて、市場は次世代GPUの戦場となる。NVIDIAは、現行のBlackwellアーキテクチャ(RTX 50シリーズ)の性能をさらに引き上げたリフレッシュ版、「SUPER」シリーズを投入してくる可能性が高い。Intelもまた、第2世代「Battlemage」アーキテクチャでミドルレンジ市場での存在感を高めようとするだろう。
このような状況下で登場するUDNAは、AMDにとってまさに正念場となる。特に、AT0ダイを搭載したフラッグシップモデルが、NVIDIAの最上位製品に対してどれだけの性能的・価格的優位性を示せるかが、市場全体の評価を決定づける。AMDがハイエンド市場で再び確固たる地位を築くことができれば、GPU市場は健全な競争環境を取り戻し、消費者にとってはより多くの選択肢と価格的なメリットがもたらされることになる。
PlayStation 6への搭載と統一プラットフォーム戦略の完成
UDNAアーキテクチャが次世代コンソール、特にSonyのPlayStation 6に採用されるという噂は、このアーキテクチャの戦略的重要性をさらに高めている。もし実現すれば、PCとコンソールが同じGPUアーキテクチャの基盤を共有することになり、ゲーム開発者にとっては開発の効率化と最適化が格段に容易になる。AMDにとっては、コンソールという巨大な市場での採用実績が、PC向けRadeon GPUのソフトウェアエコシステムを強化するという好循環を生み出す。
これは、AMDが目指す「ゲーミングからデータセンターまで」の統一プラットフォーム戦略が、コンシューマ市場の根幹から結実することを意味する。
野心的なアーキテクチャが描く未来
Kepler_L2によって示されたUDNA(RDNA 5)の姿は、単なるスペックシート上の数字の羅列ではない。それは、RDNA 4で一度しゃがみこんだAMDが、次世代に向けてより高く跳躍するための、緻密に計算された戦略の青写真である。
96 CUのフラッグシップによるハイエンド市場への挑戦、CDNAとのアーキテクチャ統合によるAI性能の追求、そしてローエンドにおけるLPDDRメモリ採用という大胆な試み。これらすべてが、AMDがGPU市場のあらゆるセグメントでリーダーシップを握ろうとする強い意志を示している。もちろん、この計画がすべて成功裏に終わる保証はない。製造プロセスの歩留まり、ソフトウェアドライバの成熟度、そしてNVIDIAという巨大な競合の次の一手など、乗り越えるべきハードルは数多い。
しかし、このリークが示す技術的な野心は、2026年以降のGPU市場が、近年稀に見るエキサイティングな競争の時代に突入することを予感させる。我々ユーザーは、このアーキテクチャの進化がもたらすであろう性能の飛躍と、それが切り拓く新たなコンピューティングの可能性を信じて待つのみである。
Sources