
AIの巨人NVIDIAに、AMDが牙を剥いた。サンノゼで開催された「Advancing AI Day」で発表された新世代AIアクセラレータ「Instinct MI350」シリーズは、そのスペック、アーキテクチャ、そしてエコシステム戦略のすべてが、絶対王者NVIDIAが築き上げた牙城を本気で切り崩しにかかるという、AMDの強い意志の表れだ。特に、液冷モデル「Instinct MI355X」は、NVIDIAの最新鋭機「Blackwell B200」と真っ向から性能を比較し、メモリ容量や一部の演算性能で凌駕すると主張している。
AI覇権戦争、新章突入:Instinct MI350シリーズの衝撃

AMDが今回投入したのは、空冷モデルの「Instinct MI350X」と、より高性能な液冷モデル「Instinct MI355X」の2つの製品だ。このラインナップは、既存の空冷データセンターから、最新の高密度・液冷データセンターまで、幅広いインフラへの導入を可能にするという戦略的な意図が透けて見える。

両モデルの中核をなすのは、AMDの最新GPUアーキテクチャ「CDNA 4」である。製造プロセスにはTSMCの最先端3nm(N3P)を採用し、実に1850億個ものトランジスタを集積。これは前世代MI300シリーズの1530億個から約21%の増加となる。さらに、AI性能に直結するメモリには、288GBという大容量のHBM3Eを搭載し、メモリ帯域幅は8TB/sに達する。
AMDのCEOであるLisa Su氏は基調講演で「我々は推論の変曲点にいる」と語り、「AIの未来は、一社やクローズドなシステムによって築かれるものではない」と、NVIDIAのクローズドなエコシステムを暗に牽制し、オープンな協業の重要性を強調した。この言葉こそ、MI350シリーズが持つ戦略の核心を突いている。
「打倒Blackwell」の野心が生んだ、驚異のスペック

MI350シリーズのスペックシートは、AMDの野心を雄弁に物語っている。特に、NVIDIAの最新アクセラレータ「Blackwell」シリーズとの比較において、その挑戦的な姿勢は明らかだ。
| 仕様 | AMD Instinct MI355X | AMD Instinct MI350X | AMD Instinct MI300X | NVIDIA B200 | NVIDIA GB200 |
|---|---|---|---|---|---|
| アーキテクチャ | CDNA 4 | CDNA 4 | CDNA 3 | Blackwell | Blackwell (2 GPU) |
| プロセス | TSMC N3P (XCD) + N6 (IOD) | TSMC N3P (XCD) + N6 (IOD) | TSMC 5nm (XCD) + 6nm (IOD) | TSMC 4NP | TSMC 4NP |
| トランジスタ数 | 1850億 | 1850億 | 1530億 | 2080億 | 4160億 |
| メモリ容量 | 288 GB HBM3E | 288 GB HBM3E | 192 GB HBM3 | 192 GB HBM3e | 384 GB HBM3e |
| メモリ帯域幅 | 8 TB/s | 8 TB/s | 5.3 TB/s | 8 TB/s | 16 TB/s |
| FP4性能 (Sparsity) | 20.1 PFLOPS | 18.45 PFLOPS | N/A | 9 PFLOPS | 18 PFLOPS |
| FP8性能 (Sparsity) | 10.1 PFLOPS | 9.2 PFLOPS | 5.2 PFLOPS | 4.5 PFLOPS | 9 PFLOPS |
| FP16/BF16 (Sparsity) | 5 PFLOPS | 4.6 PFLOPS | 2.6 PFLOPS | 2.25 PFLOPS | 4.5 PFLOPS |
| FP64性能 | 78.6 TFLOPS | 72 TFLOPS | 81.7 TFLOPS | 45 TFLOPS | 90 TFLOPS |
| TDP (消費電力) | 1400W (液冷) | 1000W (空冷) | 750W (空冷) | 1000W | 2700W (CPU含む) |
この表からいくつかの重要なポイントが読み取れる。
- メモリ容量の優位性: MI355X/350Xが搭載する288GBのHBM3Eメモリは、単体のNVIDIA B200が搭載する192GBを1.5倍上回る。これは、より大規模なAIモデルを分割せずに単一のGPUで処理できる可能性を示唆しており、推論時のレイテンシや複雑なプログラミングの削減に貢献する。
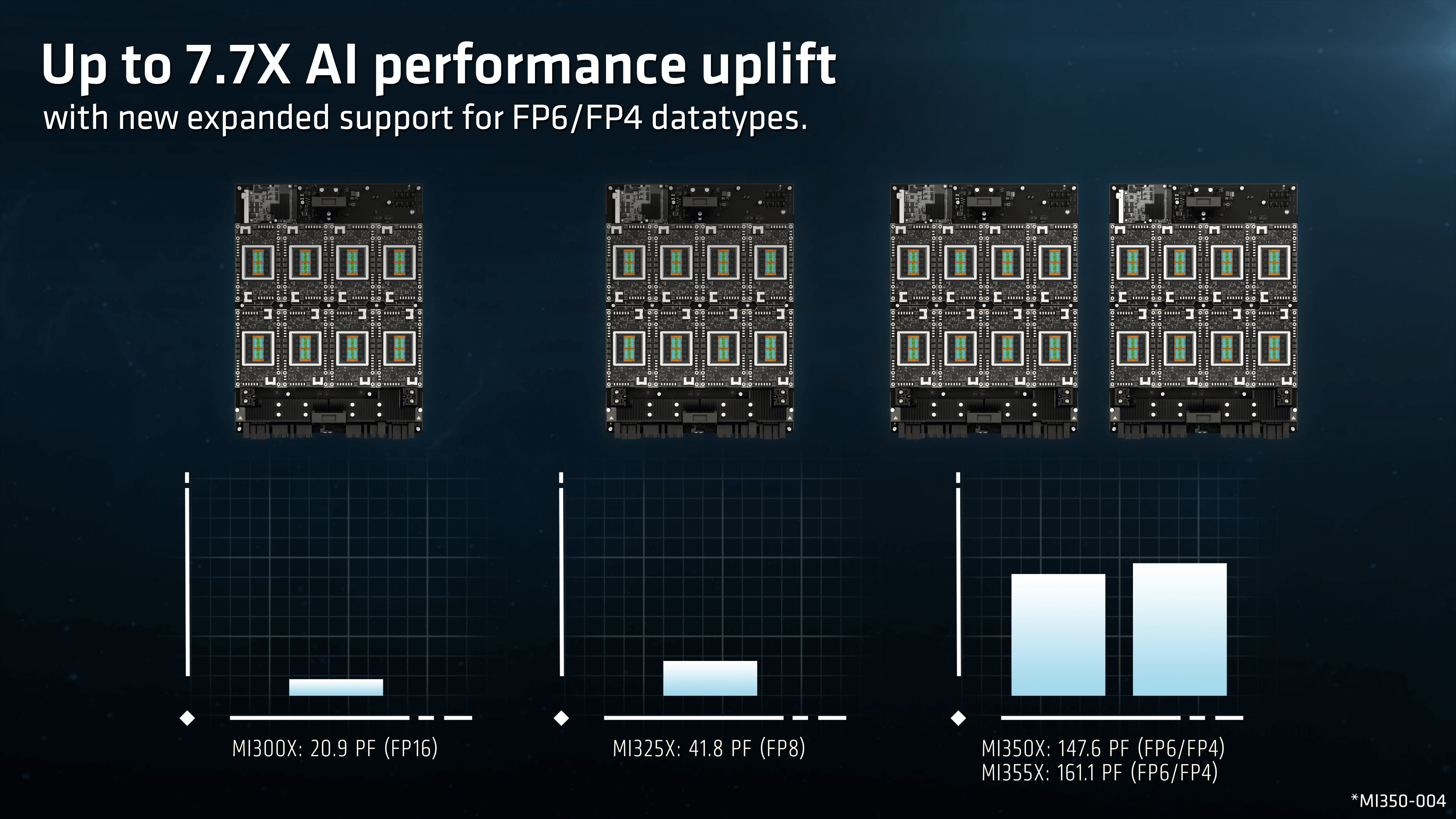
- 低精度演算での攻勢: 今回の発表で最も注目すべきは、FP4(4ビット浮動小数点数)とFP6という新たな低精度データフォーマットへの対応だ。AMDの主張によれば、MI355XはFP4性能でNvidia B200を2.2倍上回るという。AIモデルの推論処理では、精度を多少犠牲にしても計算を高速化・効率化する量子化技術が不可欠であり、この低精度フォーマットへの強力な対応は、推論市場でのシェア獲得に向けたAMDの明確な戦略である。
- 驚異的な世代間性能向上: AMDは、前世代のMI300Xと比較して、AI推論性能が最大で35倍向上したと主張している。これは単なるアーキテクチャの改善だけでなく、FP4/FP6といった新しいデータフォーマットのサポートと、それを最大限に活かすソフトウェア(ROCm 7.0)の進化がもたらした結果であり、AMDのAIへのコミットメントが本物であることを示している。
- 電力と密度のトレードオフ: MI355XのTDPは1400Wに達し、液冷が必須となる。The Registerが指摘するように、この高い消費電力は、ラックあたりのGPU搭載密度を劇的に高めるための戦略的な選択だ。AMDは、液冷ラックであれば最大128基のMI355Xを搭載可能としており、これはデータセンターのスペースとコストを重視するハイパースケーラーにとって、TCO(総所有コスト)の観点から非常に魅力的な提案となる。
見かけだけではない、内部構造の戦略的進化
MI350シリーズの強さは、スペックシート上の数字だけに留まらない。その内部構造、特にAMDが得意とするチップレットアーキテクチャの進化にこそ、同社の巧みな戦略が隠されている。

まず、MI350は前世代と同様に、複数のチップレットを組み合わせることで巨大なプロセッサを形成している。演算を担当する8つのXCD(Accelerator Compute Dies)は最新の3nmプロセスで製造され、これらを束ねる2つのIOD(I/O Dies)は6nmプロセスで製造されている。
注目すべきは、IODが前世代の4つから2つに削減された点だ。この設計の簡素化により、IOD間を結ぶ「Infinity Fabric」インターコネクトのバス幅を倍増させることに成功。これにより、チップ内部のデータ移動効率が向上し、消費電力を抑えつつ帯域幅を確保できるようになった。その結果、浮いた電力バジェットを演算性能の向上に振り分けることが可能になる。これは、性能と効率を両立させるための、非常に洗練されたエンジニアリングと言えるだろう。
ソフトウェアとエコシステム:AMDの本気度を示す「もう一つの戦場」
どれだけ優れたハードウェアを開発しても、NVIDIAの牙城であるソフトウェアエコシステム「CUDA」を崩さなければ、AI市場での勝利はおぼつかない。そのことを熟知しているAMDは、ソフトウェアとオープンなエコシステム構築に全力を注いでいる。
その中核が、オープンソースのソフトウェアプラットフォーム「ROCm」だ。今回発表された最新版「ROCm 7.0」は、推論性能を最大3.5倍、学習性能を最大3倍向上させると謳われている。
さらに重要なのが、「発売日からの完全なアップストリーム・オープンソースLinuxサポート」である。これは、開発者が特別なパッチを当てることなく、標準的なLinuxカーネルでMI350シリーズを利用できることを意味する。導入の容易さ、透明性、カスタマイズの自由度は、NvidiaのクローズドなCUDA環境を窮屈に感じている開発者や企業にとって、強力な魅力となる可能性がある。
このオープン戦略は、ハードウェアのインターコネクトにも及ぶ。AMDは、Intel、Google、Microsoftなどと連携し、オープンなGPU間接続規格「Ultra Accelerator Link (UALink)」を推進している。これは、NVIDIA独自のNVLinkに対する明確な対抗軸であり、AMDが単独で戦うのではなく、「反NVIDIA連合」を形成して業界標準を握ろうとする壮大な戦略の一環なのだ。
AMDの勝利の方程式は存在するのか?
今回の発表で、AMDは技術的にNVIDIAと互角かそれ以上に戦える「武器」を手に入れた。しかし、AI半導体というチェス盤のゲームは、それだけで決まるほど単純ではない。
NVIDIAは、10年以上にわたって築き上げてきたCUDAという名の広大で深い「堀」に守られている。圧倒的な市場シェア、膨大なソフトウェア資産、そして開発者コミュニティの慣性は、AMDにとって依然として巨大な壁である。
だが、AMDの勝利の方程式も確かに存在するだろう。
- 性能とコストでの一点突破: MI350シリーズは、特に推論性能とメモリ容量でNVIDIAに対する明確な優位性を示した。AMDが主張する「ドルあたりのトークン生成数40%向上」のようなTCO(総所有コスト)における優位性を武器に、コストに敏感なクラウド大手や企業の需要を切り崩すことができれば、突破口は開ける。
- 「オープン」という大義: AI技術が社会インフラ化する中で、特定の一社による技術の独占(ベンダーロックイン)を懸念する声は日増しに高まっている。AMDが掲げるソフトウェア(ROCm)とハードウェア(UALink)のオープン戦略は、こうした市場の声に応えるものであり、多様性と健全な競争を求める勢力を惹きつける可能性がある。OpenAIのSam Altman CEOが登壇しAMDを称賛したシーンは、この流れを象徴している。
- 市場の変化への適応: AIの主戦場がモデルの「学習」から「推論」へとシフトしつつある現在、推論に特化した性能と効率を持つMI350シリーズは、時代の要請に応える製品だ。市場の変化という追い風を捉えることができれば、勢力図を塗り替えることも夢ではない。
Instinct MI350シリーズの登場は、AI半導体市場が、単なるスペック競争から、エコシステムの思想、すなわち「クローズドな垂直統合」対「オープンな協業連合」という、より大きな構図の戦いへと移行したことを示している。AMDが投じたこの一石は、AIインフラの未来に、我々が待ち望んでいた多様性と健全な競争をもたらす、極めて重要な起爆剤となる可能性を秘めているのだ。
Sources


