
OpenAIがChatGPTのメモリ機能を、単なる「覚えておくリスト」から、長期利用を前提にした文脈合成システムへ移し始めた。2026年6月4日に発表された新しいメモリ基盤は、同社が「dreaming」と呼ぶバックグラウンド処理の上に構築され、まず米国のChatGPT Plus/Proユーザーへ提供される。追加国とFree/Goユーザーへの展開は今後数週間で進む。
この変更の要点は、ChatGPTのメモリを保存対象として扱う段階から、過去の文脈を更新する仕組みへ移すことにある。従来のsaved memoriesは、ユーザーが「これを覚えて」と明示した情報や、会話中の強い合図を手がかりに保存される仕組みだった。新しいDreamingベースの設計では、過去の複数会話から有用な文脈を合成し、時間がたって古くなった情報を更新しながら、次の会話に使える状態へ寄せる。
保存されたメモリの弱点は、保存量ではなく鮮度だった
ChatGPTのメモリは2024年4月に「保存されたメモリ」として始まった。これはユーザーが名前、好み、仕事上の制約、旅行予定のような情報を覚えさせ、将来のチャットで使えるようにする機能である。対話ごとに最初から説明し直す負担を減らす効果は分かりやすいが、保存対象は基本的に会話中に書き込まれた情報に限られる。
OpenAIはこの旧方式について、強い合図に依存していたと説明している。たとえば「7月にシンガポールへ行くことを覚えて」と言えば保存できるが、自然な会話の中に出てきた背景、継続中のプロジェクト、好みの変化までは拾いにくい。さらに、保存された事実は時間とともに古くなる。旅行予定は旅行後には過去の出来事になり、短期の仕事条件は数カ月後には意味を失う。
2025年には、OpenAIがチャット履歴を参照してメモリを自動的にキュレーションする最初のDreamingを導入した。保存されたメモリを補う仕組みとして、明示的に保存されていない会話文脈も扱えるようにするものだった。ただし、当時のDreamingは補助的な位置づけで、メモリの中核を担うには至っていなかったとOpenAIは説明している。今回の発表は、その補助的な仕組みを、より大きなメモリ基盤へ引き上げるものだ。
Dreaming V3は、長期の会話から「今使うべき文脈」を作る
OpenAIは新しいメモリを、2026年版のDreaming V3として位置づけている。評価軸は3つある。ユーザーから得た情報を将来の会話へ持ち越すこと、好みや制約に沿った応答ができること、時間の経過に合わせて文脈を更新できることである。
この3軸は、長期的な作業の前提となる文脈運用を支える応答基盤として位置づけられる。たとえば長期の開発プロジェクト、購入相談、旅行計画、健康管理、学習支援では、会話ごとに前提を失うと支援の精度が落ちる。ChatGPTが過去のカメラ構成、食事制限、居住地、作業中の案件を正しく呼び出せれば、回答は一般論からユーザー固有の選択肢に絞られる。
一方で、誤作動のリスクも同居する。古い居住地、終了済みの旅行、すでに変わった好みを現在の前提として扱うと、個人化はノイズになる。OpenAIが「staleness」「correctness」「scalability」を課題として挙げたのは、メモリが増えるほど古い情報の混入と検索コストが深刻になるためだ。数億人規模、複数年単位の会話履歴を扱うなら、保存容量を増やすだけでは追いつかない。
今回の設計は、メモリを静的な記録から、過去の材料で更新し続ける動的な状態へ移行させるものだ。OpenAIの例では、旅行前の「7月にシンガポールへ行く」は、時間が過ぎれば「2026年7月にシンガポールへ行った」へ更新される。表記上の差分は小さいが、長期関係を前提に動くAIアシスタントには必要な区別である。
メモリの可視化は、個人化の便利さと不安の接点になる
OpenAIは、新しいDreamingで合成されたメモリをmemory summary pageで確認できるとしている。ユーザー向けには、ChatGPTが把握している要点を一覧できる画面が用意され、情報の追加・更新や、話題を持ち出すタイミングの指示も行える。保存されたメモリの一覧管理に加え、合成された文脈を要約として確認できる点は、利用者側の大きな変化である。
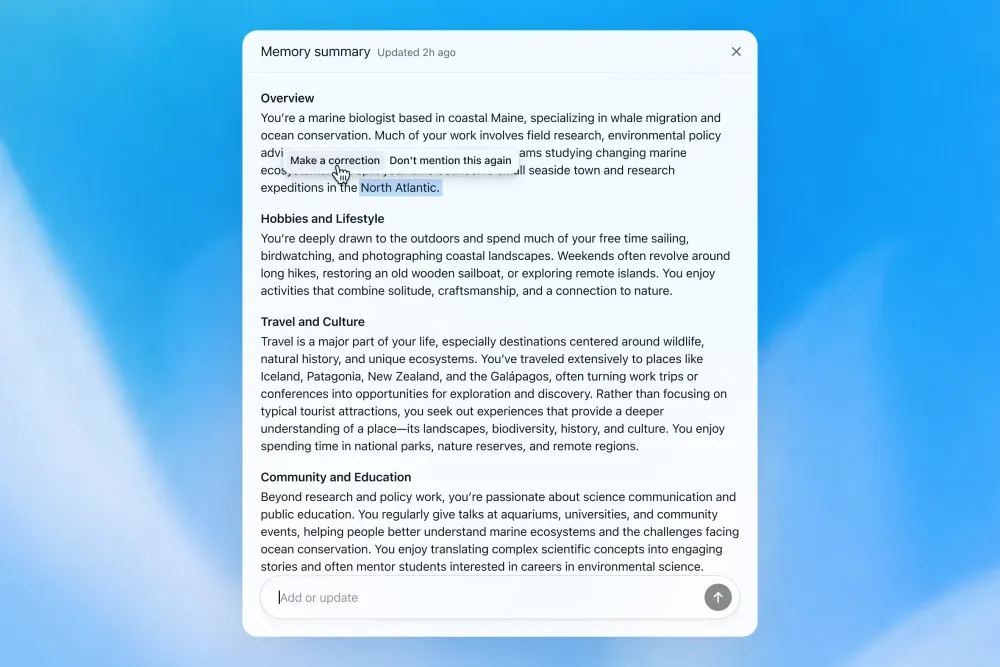
ただし、可視化は完全な監査ログではない。Memory FAQによれば、Memory Sourcesは応答の個人化に使われた情報を示す機能だが、応答を形作った全要素やソースを完全に表示するわけではない。ユーザー側に見えるのは管理しやすい形に整えられた表示で、内部の参照経路そのものではない。
プランによって参照元も異なる。Free/Goでは過去チャット、保存されたメモリ、カスタム指示がMemory Sourcesの対象になる。Plus/Proではそれに加え、ライブラリ内のファイルや接続済みGmailが参照され得る。ただしOpenAIは、ファイルとGmailについて欧州経済領域、スイス、英国では利用できないと説明している。個人化の範囲は、料金プランと地域規制の双方で決まる。
Release Notesでは、ChatGPTが過去チャット、保存されたメモリ、利用可能なファイル、接続済みGmailから関連文脈をよりよく取り込み、過去会話の検索も高速化するとされている。応答時には、関連文脈を思い出していることや個人化していることを示す表示も用意される。便利になるほど、どの情報が使われたのかを見せるUIが重要になる。
削除と一時チャットの意味は、以前より重くなる
メモリが強くなるほど、ユーザー側の制御も実務的な意味を持つ。OpenAIのHelp Centerでは、メモリには「Reference saved memories」と「Reference chat history」の2つの設定があると説明されている。前者はユーザーが明示的に覚えさせた情報、後者は過去チャットから今後の会話を役立てるために参照される情報である。
設定は柔軟に変えられるが、挙動には把握しておきたい点もある。保存されたメモリをオフにしても、すでに保存された内容が自動で削除されるわけではない。チャットを削除しても、その会話から保存された保存されたメモリは消えない。完全に取り除くには、設定画面などで保存されたメモリを削除し、元になったチャットも削除する必要がある。
一時チャットは、より明確な避難経路になる。Memory FAQによれば、一時チャットは既存のメモリを使わず、新しいメモリも作らず、履歴にも表示されない。機密性の高い相談や、一度きりの調査、普段の人格や嗜好から切り離したい作業では、このモードの価値が上がる。個人化が標準に近づくほど、個人化しない会話を選べることも機能の一部になる。
また、OpenAIは共有チャットではMemory Sourcesを表示しないとしている。これは共有相手に自分のメモリ由来の情報を見せないための設計だが、共有された会話だけを見ても、どの個人文脈が応答に影響したかは分からない。チームでChatGPTの出力を共有する場面では、この非表示性を理解しておく必要がある。
Free展開を可能にした5分の1の計算コストが示すもの
今回の発表で見落としにくい数字は、DreamingをFreeユーザーへ提供するための計算コストを約5分の1に下げたという点だ。OpenAIは、この効率化によって今後数週間でFreeユーザーにもDreamingを展開し、Plus/Proのメモリ容量も増やせるとしている。
この数字は、メモリをChatGPTの標準体験として位置づける基盤を意味する。長期記憶を持つAIは、一人ひとりに合わせた応答を作れる一方で、過去チャットの検索、文脈の選別、古い情報の更新に計算資源を使う。コストが高いままなら、個人化は高額プランの差別化機能にとどまりやすい。計算効率の改善で、メモリは一部プランの高付加価値機能から、ChatGPTの共通基盤へ移行しやすくなる。
OpenAIは今回のメモリを「最も高性能なメモリシステム」と表現しているが、実際の評価は導入後の失敗例で決まる。思い出すべき過去文脈を拾えるか、古い情報を現在の条件として扱わないか、敏感な情報を不必要に持ち出さないか。ユーザーが手元で確認できるMemory SummaryやMemory Sourcesは、その検証の窓口になる。
ChatGPTが毎回まっさらな相手から、過去のやり取りを持ち越す相手へと変わると、AIとの会話は検索や一問一答から継続的な作業環境へ移行する。ただし、透明性と削除手段が伴わなければ、誤った前提を抱えたまま会話が進む危うさも増す。Dreaming V3の真価は、思い出すべき時と忘れるべき時を選別できる精度で測られる。


