
ChatGPTやClaude、GeminiといったLLM(大規模言語モデル)を日常的に利用する中で、多くのユーザーが直面する不可解な現象がある。長時間の対話や複雑なタスクをこなすうちに、AIが以前の指示を忘れたり、重要な文脈を無視した回答を始めたりする現象だ。業界ではこれを「コンテキストの腐敗(Context Rot)」と呼ぶ。
従来の解決策は、コンテキストウィンドウ(一度に処理できるトークン数)を拡張するか、RAG(検索拡張生成)を用いて外部データベースから情報を引っ張ってくるかの二択であった。しかし、100万トークンを超えるコンテキストウィンドウを持たせても、モデルは「迷子」になり、情報の海に溺れる。一方で従来のRAGは、断片的な情報の取得には長けているが、文脈をまたぐ複雑な推論には無力だった。
この膠着状態を打破するブレイクスルーが、中国と香港の研究チーム(北京人工知能研究院、中国人民大学、北京大学、香港理工大学)によって発表された。彼らが開発した「General Agentic Memory (GAM)」は、従来の「静的な記憶」の概念を根底から覆し、ソフトウェア開発における「JIT(Just-in-Time)コンパイル」の哲学をAIの記憶に応用した画期的なアーキテクチャである。
パラダイムシフト:AOTからJITへ
GAMの本質を理解するには、まず既存のアプローチとの決定的な違いを把握する必要がある。
従来の限界:Ahead-of-Time (AOT) の呪縛
既存のメモリシステム(例:MemGPTや従来のLangChainベースのメモリ)の多くは、AOT(Ahead-of-Time)コンパイルの原則に従っている。これは、対話が発生した時点で、将来何が重要になるかを予測し、事前に要約(圧縮)して保存する手法だ。
しかし、この手法には致命的な欠陥がある。「将来どのような質問が来るか」が不明な段階で情報を圧縮するため、不可逆的な情報の損失が発生するのだ。些細に見えて切り捨てた詳細が、後の推論で決定的になるケースに対応できない。
GAMの革新:Just-in-Time (JIT) の導入
GAMはこれを逆転させる。「JIT(Just-in-Time)コンパイル」の原則に基づき、「質問が来てから初めて、その文脈に合わせて記憶を最適化する」というアプローチを採る。
平時は情報を最小限の処理で保持し、必要になった瞬間に、エージェントが能動的に記憶の海を探索・再構成する。これにより、情報の鮮度と詳細さを維持しつつ、無限に近い記憶容量と高精度な回答生成を両立させることに成功している。
アーキテクチャ解剖:デュアルエージェントシステム
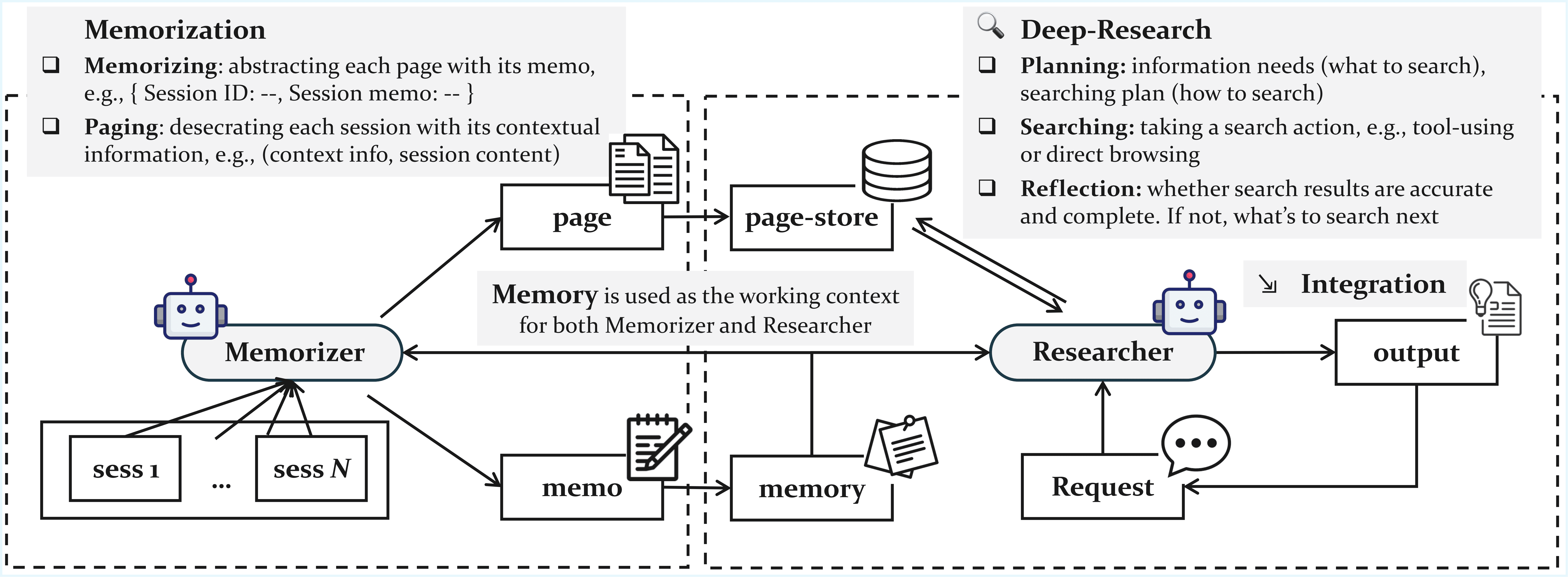
GAMの構造は、人間の脳の働き、あるいは高度に組織化された図書館の運営に似ている。システムは「Memorizer(記憶者)」と「Researcher(研究者)」という2つの専門化されたLLMエージェントによって構成される。
Memorizer(記憶者):情報のアーキバリスト
バックグラウンドで常時稼働するエージェント。ユーザーとの対話(ストリームデータ)を受け取り、以下の2つの処理を行う。
- 軽量メモ化 (Memorizing):
対話のセッションごとに、簡潔で構造化された「スナップショット(要約)」を作成する。これは目次やインデックスのような役割を果たし、後述するResearcherが探索する際の「地図」となる。 - ページングと完全保存 (Paging):
ここが重要だ。GAMは要約だけでなく、対話の全履歴を「Page Store」と呼ばれるデータベースに完全な形で保存する。 各セッションはヘッダー(文脈情報)付きの「ページ」として管理され、検索性を高めるためのタグ付けが行われる。Anthropicの「Contextual Retrieval」に近い概念だが、これを動的なエージェントシステムに組み込んでいる点が新しい。
Researcher(研究者):能動的な探偵
ユーザーから質問(クエリ)が投げられた瞬間に起動するエージェント。単にデータベースを検索するのではなく、「Deep Research(深層調査)」と呼ばれる反復プロセスを実行する。
- Step 1: 計画 (Planning)
ユーザーの要求を分析し、Memorizerが作成した「地図(軽量メモリ)」を参照して、どこに答えがありそうかの仮説を立てる。ここでは「Chain-of-Thought(思考の連鎖)」推論が用いられ、必要な情報を特定する。 - Step 2: 探索 (Searching) 以下の3つのツールを駆使して、Page Storeから具体的な情報を引き出す。
- Vector Search: 意味的な類似性に基づく検索(概念的な問いに有効)。
- BM25 Search: キーワード一致検索(具体的な固有名詞や日付に有効)。
- Page ID Access: 特定のページIDへの直接アクセス(文脈上、直前の会話などを参照する場合)。
- Step 3: 省察と反復 (Reflection & Iteration)
これがGAMの真骨頂である。取得した情報で十分かどうかをエージェント自身が判断(Reflection)する。「情報不足」と判断すれば、新たな検索クエリを生成し、再度探索を行う。この自己修正ループにより、断片的な情報をつなぎ合わせ、複雑な推論を完成させる。
ベンチマーク分析:RAGと長文脈モデルの敗北
論文に示された実験結果は、現在のAI業界にとって衝撃的なものである。GAMは、従来のRAGや、巨大なコンテキストウィンドウを持つ最新モデル(GPT-4o-mini, Qwen2.5-14B-Instruct)と比較して、圧倒的なパフォーマンスを叩き出した。
RULERベンチマークでの完勝
特に注目すべきは、長文脈理解を測る「RULER」ベンチマークにおける結果だ。
- Multi-hop Tracing (MT) タスク: 文脈全体に散らばる変数の値を追跡する、極めて負荷の高いタスク。
- GAM: 正解率 90%以上
- RAG: ほぼ 0%(失敗)
- Long-Context LLM: コンテキストウィンドウに全情報を入れても、ノイズに埋もれて精度が大幅に低下。
HotpotQAでの優位性
複数の文書をまたいで推論する必要があるHotpotQA(56K, 224K, 448Kトークン)においても、GAMは一貫してベースラインを上回った。
- GAM (HotpotQA 448K): F1スコア 59.81 (GPT-4o-miniベース)
- RAG: F1スコア 54.01
- A-Mem (既存メモリ手法): F1スコア 31.37
ここから読み取れる事実は明確だ。「コンテキストウィンドウを広げれば解決する」という単純な力技は、情報量が増えるにつれて「迷子」になるリスクを高めるだけである。また、静的なRAGは、単純な事実検索には使えるが、文脈を縫い合わせる「Agentic(エージェント的)」な思考には対応できない。
なぜGAMは機能するのか?
単なるスペック比較を超えて、GAMが示唆する技術的な意味を掘り下げてみよう。
「検索」から「調査」への進化
従来のRAGは「Google検索」のようなものだ。キーワードを入れて、上位の文書を読む。対してGAMのResearcherは「調査報道記者」に近い。一次資料(Page Store)にあたり、内容を読み込み、足りなければ別の資料を探し、裏取りをしてから記事(回答)を書く。
この「反復的な内省(Iterative Reflection)」こそが、ハルシネーション(幻覚)を抑制し、論理的な整合性を保つ鍵となっている。
計算リソースの動的な配分
GAMは「Test-time Compute(推論時の計算量)」をスケーリングできる特性を持つ。簡単な質問には即答し、複雑な質問にはResearcherが何度も思考と検索を繰り返すことで時間をかけて答える。これはOpenAIのo1モデルなどが採用している「推論時間の拡張」と軌を一にするトレンドであり、「モデルのサイズ」ではなく「思考の時間」で賢さを生み出す新しいパラダイムだ。
コンテキスト・エンジニアリングの自動化
Anthropicなどの先端企業は現在、プロンプトエンジニアリングから「コンテキストエンジニアリング(AIにどう記憶を持たせるか)」へ焦点を移している。GAMは、Memorizerによる構造化とResearcherによる再構成を通じて、この高度なエンジニアリングを自動化しているといえる。ユーザーは何もせずとも、AIが勝手に最適なコンテキストを構築してくれるのだ。
オープンソースによる民主化
GAMのコードとデータはGitHub(VectorSpaceLab/general-agentic-memory)で公開されている。これは、巨大テック企業だけでなく、個人の開発者や中小企業が、GPT-4クラスの「記憶力」を持つエージェントを構築可能になることを意味する。特に、パーソナルアシスタント、TRPGのNPC、長期的なコーディングプロジェクトの管理などにおいて、革命的な応用が期待される。
競合技術との対比
- DeepSeek: テキスト画像を圧縮してOCR処理するアプローチで長文脈に対応しようとしている。これは「圧縮効率」のアプローチだ。
- Semantic OS (上海の研究): 脳のように忘却と適応を行うシステム。
GAMはこれらに対し、「全ての履歴を保持しつつ(ロスレス)、必要な時だけ全力で探す(オンデマンド)」という、ストレージコストはかかるが精度を最優先するアプローチをとる。エンタープライズや専門職(法務、医療、研究)においては、GAMのアプローチが好まれる可能性が高い。
記憶の「コモディティ化」
GAMのようなアーキテクチャの登場により、LLM単体の「コンテキストウィンドウサイズ競争」がは終焉に向かうかもしれない。100万トークンを一度に入力するよりも、GAMのような優れたメモリ管理システムを介して14Bクラスの軽量モデルを動かす方が、コストパフォーマンスも精度も高くなるからだ。これは、AI開発の主戦場が「モデルの巨大化」から「エージェント・アーキテクチャの最適化」へと移行している証である。
General Agentic Memory (GAM) は、単なる新しいメモリ機能ではない。それはAIが「過去のデータ」をどのように扱い、「現在のタスク」にどう応用するかという認知プロセスそのものの再定義である。
静的な要約(AOT)から動的な調査(JIT)への転換は、AIエージェントが真に自律的なパートナーとして機能するために不可欠な進化だ。情報の損失を許容しないこのシステムは、ビジネスや学術研究など、高い信頼性が求められる領域で、RAGに代わる新たなデファクトスタンダードとなる可能性を秘めている。
論文
参考文献
- GitHub: VectorSpaceLab/general-agentic-memory