
Microsoftが開発する小型言語モデル(SLM)群「Phi」シリーズに、目覚ましい「推論能力」を実装した新モデル群「Phi-4」が加わった。わずか一年前、Phi-3をもってSLMの潜在力を世に示したMicrosoftであったが、今回のPhi-4、取り分けPhi-4-reasoningとPhi-4-reasoning-plusは、そのコンパクトなサイズからは想像し難い性能を叩き出し、一部の評価基準においては遥かに巨大なAIモデルをも凌駕すると報告されている。Phi-4の能力は、AIがパラメータ数に比例するという通説に挑戦状を叩きつける物であり、「効率」と「質」こそが新たな価値尺度となり得ることを強く示唆する物と言えるだろう。
推論能力が拓く新境地:Phi-4ファミリーの解剖
まず、今回の発表の核となるPhi-4ファミリーだが、主に三つの新しい「推論モデル」から構成される:
- Phi-4-reasoning: 140億パラメータを有するオープンウェイトの推論モデル。複雑な課題処理において、巨大モデルと比肩しうる能力を秘める。
- Phi-4-reasoning-plus: Phi-4-reasoningを基盤とし、強化学習などの追加訓練を経て、より多くの計算資源(トークン)を投入することで一層の高精度を追求した上位版。
- Phi-4-mini-reasoning: わずか38億パラメータという極めて小さな設計。モバイル端末やエッジコンピューティングといった、計算資源が限られる環境下での数学的思考力に特化して最適化されている。
「推論モデル」とは、従来の大規模言語モデル(LLM)がパターン認識や情報の引き出しに長けていたのに対し、推論モデルは、入り組んだ問題に対し複数の思考段階を経、内部での熟考を重ねることで、より論理的で精度の高い解を導き出す能力に秀でたAIモデルだ。この能力は、数学の証明、複雑な事業計画の策定、あるいは科学上の難題への挑戦といった場面で決定的に重要であり、これまでは主に巨大な最先端モデルのみが有する能力と見なされてきた。Microsoftは、選び抜かれた高品質データと洗練された訓練技法(後述)を武器に、この高度な推論能力を、驚くほど凝縮されたサイズのモデルに封じ込めることに成功したのだ。
データが示すPhi-4の真価
Phi-4を端的に言い表すならば、「小型にして高性能」という言葉がピッタリだろう。実際に、Microsoftが開示したデータが、その実力を物語っている。
Phi-4-reasoning & reasoning-plus:140億パラメータが起こす波紋
140億パラメータのPhi-4-reasoningおよびその強化版reasoning-plusは、多数のベンチマークにおいて注目すべき成果を数多く記録している。特に注目に値するのは、数学や科学領域における推論能力の高さだ。
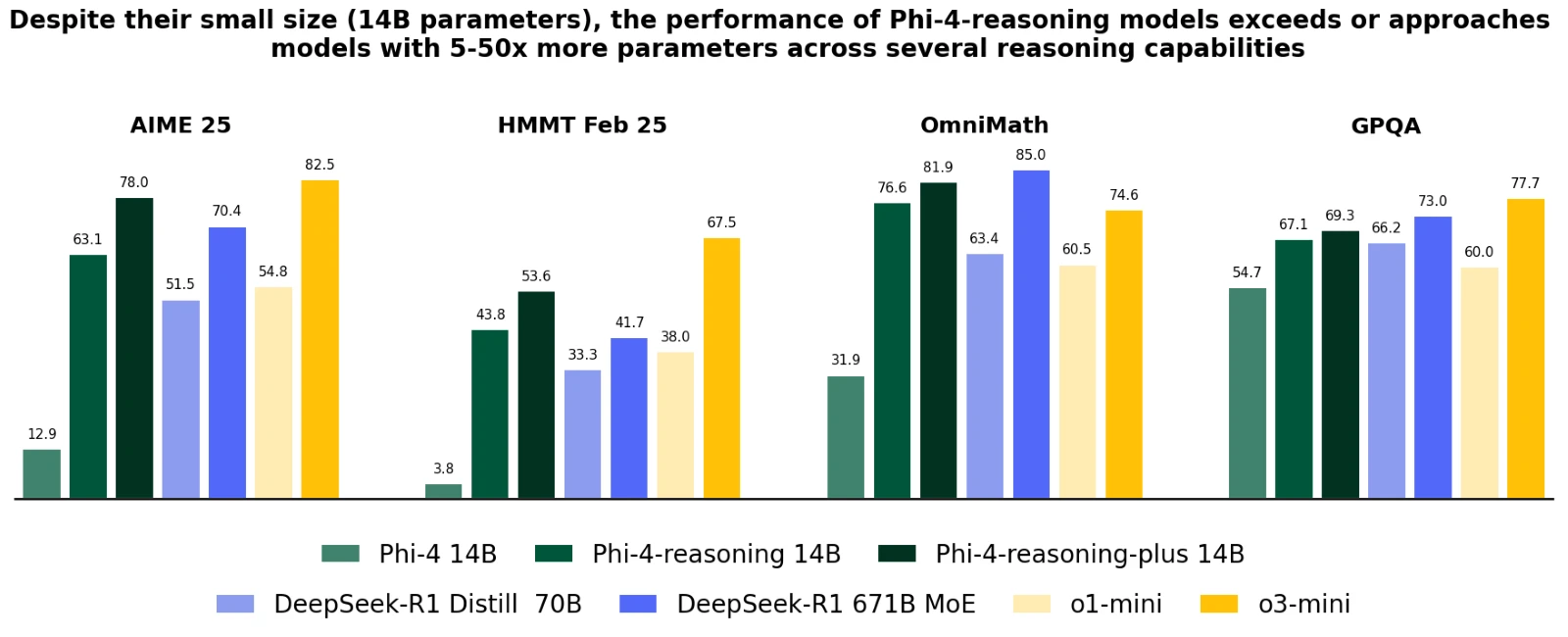
- 巨大モデルとの対峙: Microsoftの報告によれば、Phi-4-reasoningとreasoning-plusは、OpenAIのo1-miniや、700億パラメータを擁するDeepSeek-R1-Distill-Llama-70Bなど、自らを遥かに上回る規模のモデルを多くのベンチマークで凌駕する性能を示したという。
- AIME 2025での卓越性: 更米国数学オリンピック予選であるAIME 2025テストにおいて、これらの14Bモデルは、実に6710億パラメータを持つ巨大モデルDeepSeek-R1(完全版)と互角、あるいは一部指標ではそれを超えるパフォーマンスを見せたとされる。パラメータ数で約48倍もの隔たりがあるモデルと伍する、あるいは凌駕するというPhi-4は、フェザー級選手がヘビー級選手を打ち倒すような規格外の実力を持つと言えるだろう。
- 広範な適用能力: コーディング、アルゴリズム的問題解決、計画立案といった多岐にわたる分野でも、既存のPhi-4から飛躍的な改善が確認され、DeepSeek-R1-Distill-70Bを凌ぎ、巨大なDeepSeek-R1の背中が見えるレベルにまで迫る性能を発揮すると報告されている。
この卓越した性能の背景には、精緻な訓練プロセスが存在する。Phi-4-reasoningは、質の高いWebデータに加え、OpenAIのo3-miniから抽出された、入念に吟味された推論デモンストレーションデータを用いてファインチューニングが施された。さらにreasoning-plusでは強化学習が導入され、より多くのトークン(Phi-4-reasoning比で1.5倍)を処理することで、精度を一段と引き上げている。
Phi-4-mini-reasoning:モバイル/エッジにも推論モデルを
他方、38億パラメータという際立ったコンパクトさが特徴のPhi-4-mini-reasoningもまた、その規模からは想像し難い能力を見せつけている。
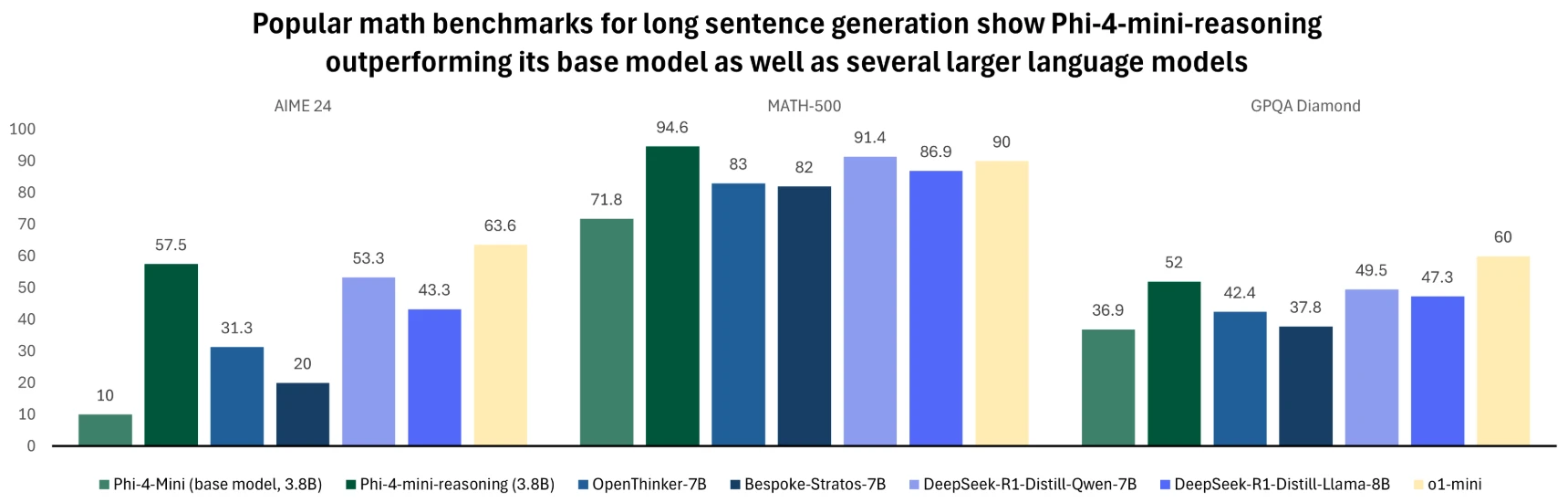
- 訓練データの源泉: このモデルは、中国のDeepSeek社のR1モデルが生み出した、100万問を超える多様な合成数学問題(中等教育レベルから博士課程レベルまで網羅)を利用してファインチューニングを受けた。まさに「AIがAIを指導する」構図であり、専門知識を極めて効率的に習得した格好だ。
- 想定される活用場面: その小型性と高効率性により、教育用アプリケーション、組み込み型チューターシステム、スマートフォンやエッジデバイス上での低遅延推論処理などに理想的な適性を持つ。
- 性能評価: サイズこそ小さいものの、OpenThinker-7BやDeepSeek-R1-Distill-Qwen-7Bといったモデルを一部の評価で上回り、数学的問題解決能力においてはOpenAIのo1-miniに匹敵、あるいはそれを超える結果も示されていると伝えられる。
Phi-4ファミリーの登場は、「AIの能力はパラメータ数に比例する」という単純な等式がもはや絶対ではないことを示唆している。では、彼らはなぜ「小さくても高性能」なのか?
「小さくても高性能」理由:Phi-4 訓練戦略の核心
Phi-4シリーズが示す驚くべき効率性の根源は、その独特な訓練戦略にある。「量」よりも「質」を徹底的に追求したアプローチと言えよう。
- データ品質への執着: Microsoftは、単に膨大なデータを投入するのではなく、入念に選別(キュレーション)された高品質なWebデータや、推論プロセスを明示する質の高いデモンストレーションデータ(例:o3-mini由来)の活用を最重視した。
- 合成データの戦略的注入: 特に推論能力の獲得においては、他の高性能AI(DeepSeek-R1など)が生成した、大量かつ多様性に富む「合成データ」が極めて効果的に用いられた。これにより、特定の技能(例えば数学的推論)を集中的かつ効率的に学習させることが可能となる。いわば、教師役のAIが生徒役のAIのレベルに合わせて最適な練習問題を無限に生成するようなものだ。
- 高度な訓練技法の融合: 教師ありファインチューニング(SFT)、強化学習(RL、具体的にはRLHFやDPO、GRPOアルゴリズムなど)、蒸留といった複数の先進的テクニックが巧みに組み合わされている。これにより、モデルの知識基盤だけでなく、望ましい応答スタイルや安全性をも同時に涵養しているのだ。
- 思考プロセスの明示化 (<think>タグ): VentureBeatの報道によれば、訓練過程で <think> と </think> という特殊なタグが導入された点も注目に値する。これによってモデルは、最終的な解答に至るまでの中間的な思考プロセス(Chain-of-Thought)を明確に分離して生成するよう学習する。これは、モデルの思考過程の透明性を高め、長大で複雑な問題に対する一貫性と正確性を向上させる効果が期待される。
Phi-4の成功は、AI開発において、巨大なデータセットと潤沢な計算資源だけが成功の条件ではないことを証明している。データの質、戦略的な合成データの利活用、そして洗練された訓練技法こそが、効率的かつ高性能なAIを誕生させる真の鍵なのかもしれない。
Windowsから開発の最前線まで:Phi-4の展開と開発者への開放
Phi-4ファミリーは、研究機関の壁の中に留まる存在ではない。既に実用化への道筋が敷かれ、開発コミュニティに対しても広く門戸が開かれている。
- Copilot+ PCとの緊密な連携: Microsoftは、Phiモデル群をWindowsオペレーティングシステムに深く統合する動きを見せている。特に「Phi Silica」と呼称されるNPU(Neural Processing Unit)向けに最適化されたバージョンは、新型Copilot+ PCに標準搭載され、OSの管理下でメモリ上に常駐。これにより、極めて高速な応答速度と優れた電力効率が実現される。
- 具体的な応用事例: 現時点でも、画面上のあらゆるコンテンツに対して知的な操作補助を行う「Click to Do」機能や、Outlookにおけるオフライン環境下でのメール要約機能などにPhi Silicaが活用されている。今回発表されたPhi-4-reasoningモデル群も、将来的にはCopilot+ PCのNPU上で動作するよう最適化が進められる予定である。
- 開発者コミュニティへの提供: Phi-4-reasoning、reasoning-plus、mini-reasoningの三モデルは全て、オープンウェイト(モデルの内部パラメータが公開されている状態)として、MicrosoftのAzure AI Foundryおよび広く利用されるAIプラットフォームHugging Faceを通じて提供されている。
- 柔軟性の高いライセンス体系: 特にPhi-4-reasoning-plusは、寛容なMITライセンスの下で提供されており、商用利用やモデルの改変、再配布などが比較的自由に行える。これは、企業や個々の開発者がPhi-4を自社のサービスやプロダクトに組み込む際の障壁を大幅に低減させる措置である。
- 活用のための指針: Microsoftは、これらのモデルの能力を最大限に引き出すための推奨設定(推論パラメータやシステムプロンプトの書式など)に関する情報も提供している。特に、対話形式で利用し、段階的に思考を進めるよう指示するプロンプトを与えることで、最適なパフォーマンスが得られるとされている。
Phi-4ファミリーは、高性能な推論能力を、より身近なデバイスや、従来は計算資源の制約からAI活用が難しかった環境にもたらす潜在力を秘めている。オープンな提供形態と相まって、今後、想像を超える多様なアプリケーションでの活用が期待される。
見過ごせない視座:責任あるAI開発へのコミットメント
強力なAIモデルの開発と普及には、倫理的な配慮と安全性の確保という責務が常に伴う。Microsoftもこの点を深く認識しており、Phiモデルの開発においては、同社が掲げる責任あるAIの諸原則(説明責任、透明性、公平性、信頼性と安全性、プライバシーとセキュリティ、包括性)に準拠していることを強調している。
- 安全性強化のための訓練: Phiファミリーは、安全性担保を目的とした特別な訓練工程(ポストトレーニング)を経ている。これにはSFT、DPO、RLHFといった手法が用いられ、有用性(Helpfulness)と無害性(Harmlessness)に焦点を当てたデータセットや、安全に関わる様々な質疑応答データが活用されている。
- 継続的なリスク評価: Microsoft内部の専門部隊(AI Red Team)による敵対的テスト(Red Teaming)や、Toxigenのような評価ツールを用いたベンチマーキングを通じて、潜在的なリスクの同定と低減に向けた継続的な努力が払われている。
- 限界の認識と透明性の確保: 同時にMicrosoftは、いかなるAIモデルも完全無欠ではなく、固有の限界を有することを率直に認めている。開発者や利用者は、これらのモデルを特定の目的、とりわけ社会的な影響が大きい領域で利用する際には、その性能、安全性、公平性を事前に慎重に評価する必要があると警鐘を鳴らしている。詳細な情報については、各モデルに付随して提供される「モデルカード」を参照することが推奨される。
Phi-4のような強力かつアクセスしやすいモデルが登場する中で、開発者と利用者の双方が、その能力と限界を正確に理解し、責任ある姿勢で技術と向き合うことの重要性は、ますます高まっていると言えよう。
Phi-4が描き出すAIの未来像
今回のPhi-4ファミリーの登場は、AIの進化における潮流が大きく変わってきている事を改めて認識させられる物だ。
これまでのパラメータ数を競う「規模」の追求から、より少ない計算資源で高い能力を引き出す「効率」へと、競争の軸足が明らかに移動し始めている。これは、中国のDeepSeekが与えた衝撃によるものだが、Phi-4は、この流れを更に加速させるかもしれない。同時に、これまで一部の巨大モデルの専売特許であった高度な「推論能力」が、より小型でアクセスしやすいモデルにも実装され始めたことは、AIが単なる情報検索ツールから、真に「思考するパートナー」へと役割を変えていく可能性を秘めている。
さらに、MicrosoftがPhi-4をオープンウェイト、一部は寛容なライセンスで公開したことは、AI技術の民主化とイノベーションの加速を促すだろう。これは、特定のパートナー技術への依存を避け、自社のクラウドやOSプラットフォーム全体でAI活用を推進しようとするMicrosoft自身の多層的な戦略とも符合する動きに見える。
こうした変化の根底には、AIの性能を左右するのが単なるデータの量ではなく、その「質」と、いかに「賢く」モデルを訓練するかという技術的な洗練度である、という認識が深まっていることがある。Phi-4は、まさにデータ戦略と訓練手法の勝利と言えるだろう。
Sources


