AIモデルの演算要求は、データセンターのインフラ設計の前提を次々と塗り替えている。imecのCEOであるPatrick Vandenameeleは、同社の国際技術フォーラム(ITF)でその構造的な問題を端的に述べた。「AIデータセンターは今やギガワット単位で測られる。スケールアップはGPUを最大のダイサイズで集積し、ラック単位で並列動作させ、さらに多数のラックを接続するという一貫した戦略で進んできた。しかし電力消費はほぼ線形に増加し続けており、スケールしているとは言えない」。
この非効率の深刻さは、次世代AIシステムの試算によって明確になる。マルチエージェントAIシステムへの移行が進む中、研究者らはこれらのシステムが既存の大規模言語モデルの150倍の演算能力を必要とすると見積もっている。現在の電力消費とほぼ線形の関係が続けば、150倍の演算は同程度の電力増加を意味する。物理的・インフラ的な限界に直面するのは避けられず、演算効率そのものを改善しない限り、次のスケール段階へ進む手段は存在しない。
Vandenameeleが提示する解決の方向性は、「アルゴリズム、デバイススケーリング、通信ファブリック、アーキテクチャの各改善は乗算的に作用する」という点にある。個別に10%改善しても全体では数%の改善に留まるが、これらを協調して最適化すれば、積の形で10年間に10倍の演算効率向上が達成可能だという見立てである。
imec 2026年版ロードマップの具体的な変更点
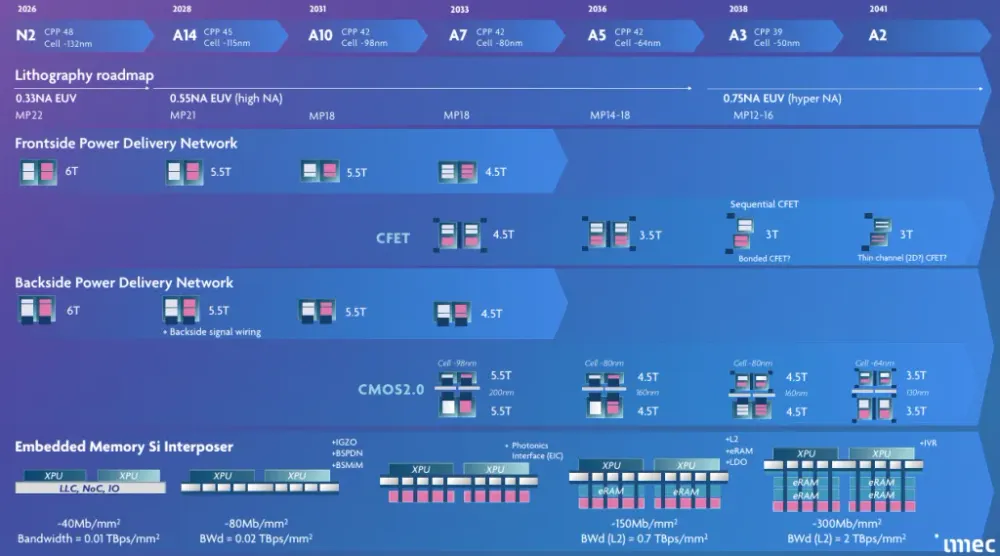
imecが公開した最新ロードマップは、2nmノード(現在の最先端)から2040年頃の2オングストローム(0.2nm相当)ノードに至る技術ロードマップを提示している。そのうちいくつかの更新点は、業界が進む方向を具体的に示している。
CFETトランジスタ(相補型電界効果トランジスタ)の量産への本格移行は、7オングストローム(0.7nm)ノードの時代、おおむね2033年前後を想定している。CFETはnFETとpFETを垂直に積層する構造で、従来のGAA(Gate-All-Around)ナノシートアーキテクチャに比べてダイ面積あたりのトランジスタ密度を大きく向上させる。ただし量産には表面・裏面の双方の金属配線(フロントサイドおよびバックサイドメタライゼーション)が不可欠であり、製造プロセスの複雑度が格段に上がる。
Contact Poly Pitch(CPP)のスケーリングは10オングストロームノード(2030年頃)で実質的に頭打ちになるという見通しも示された。これはトランジスタの物理的な微細化という意味でのムーアの法則が、このポイントで転換期を迎えることを意味する。以降の密度向上は、単純な縮小ではなく3次元積層や新材料の採用、CMOS 2.0と呼ばれるアーキテクチャ変革によって担われる。
新たに追加されたのが「組み込みメモリインターポーザー」のロードマップである。XPU(演算チップ)とメモリの物理的距離を縮めることで、データ移動に伴うエネルギー損失と帯域幅の制約を緩和する狙いがある。現在のパッシブシリコンインターポーザーはサイズが大きくなるほど歩留まりが低下し、修復も困難になるという問題を抱えており、この新アーキテクチャはその解の一つとして提案されている。
CMOS 2.0が再定義するチップ設計の空間
7オングストロームノードに対応するCMOS 2.0は、ウェーハの裏面(バックサイド)を機能的な配線層として活用する設計思想に基づく。フロントサイドにはロジック、RF、一部のメモリを階層ごとに配置し、バックサイドには電力供給ネットワーク(PDN)を分離する構成となる。これにより、電力供給と信号配線の干渉を減らし、チップ全体の電力効率を改善する。
imecのシニアフェローであるEric Beyneは、この延長線上で「体積的3D(Volumetric 3D)」という構造を提案している。現在のパッシブシリコンインターポーザーを大型化し続ける代わりに、インターポーザーを湾曲させてHBMモジュールをDIMMカードのようにスロットに差し込む形状を採る。インターポーザーの面積が小さくなることで歩留まりが改善され、垂直スロットにマイクロチャネル冷却を組み込むことができ、上面にはSoCを搭載して主冷却を確保する構成になる。Beyneは「この構造はまだ開発初期段階にある」と注記しており、量産適用には研究段階での検証が必要な状態にある。
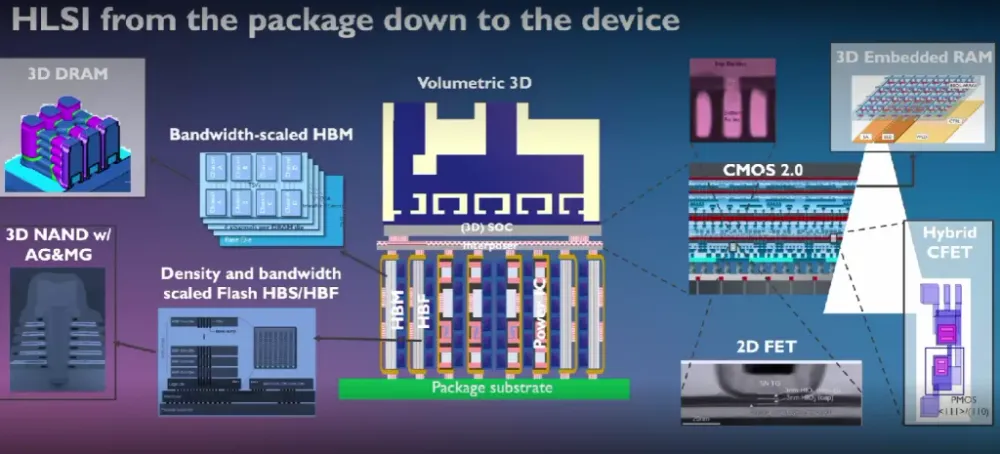
インターコネクト材料の観点では、10オングストロームノードにおいて半ダマシン構造のルテニウムまたはモリブデン配線にエアギャップ誘電体を組み合わせる手法が初めて採用される見通しである。これらの材料は銅配線より高抵抗であるものの、エアギャップによる寄生容量の低減と組み合わせることで、配線遅延と消費電力の改善が見込まれる。
フィジカルAIが要求するアーキテクチャの転換
データセンター向けAIと「フィジカルAI」(ロボットや自律システムに搭載されるAI)では、ハードウェアへの要求は次元が違う。AMDのアダプティブ・エンベデッドコンピューティンググループのSVPであるSalil Rajeは、クラウドAIについて「自動化されており、レイテンシー許容度が高く、集中型であり、クラウドは非常に寛容だ。プロンプトを送り、応答を待つ。時間がかかっても長く待てばよい。間違えても新しいプロンプトで再試行できる」と述べた上で、フィジカルAIとの決定的な差異をこう語った。「次の章は違う。病院や家庭では、やり直しは効かない」。
この違いは、マイクロ秒単位の決定論的な応答時間という要件に集約される。Rajeによれば、フィジカルAIにおける制御系はマイクロ秒単位の処理を毎サイクル、継続的に完了しなければならない。このタイムバウンドな処理要件に応えるのが、FPGAやアダプティブSoCを中心とするアダプティブアーキテクチャであり、システム全体の協調制御にはCPUが用いられる。
ロボティクスOEM上位150社が共通して求めるのは、決定論的な動作保証と予測可能なタイミング特性、さらにオープンアーキテクチャによって産業用アームからヒューマノイドロボットまで同一プラットフォームで動かせるスケーラビリティである。この要求がASICではなく再構成可能なアーキテクチャへの需要を支えている。
こうした決定論的AIのエッジ実装を支えるシリコン側でも、急速な変化が起きている。TSMCのKevin Zhangは、エッジデバイスのノード移行が加速していることを具体的な数字で示した。モバイルフォンのアプリケーションプロセッサーは2026年末までに2nmへ移行し、RF用デバイスは6nm FinFET、カメラのイメージシグナルプロセッサーは12nm FinFETへそれぞれ移行する。Zhangが特に強調したのは動作電圧であり、0.4Vまでの低電圧化によってスイッチング電力を最大70%削減できるという。これはエッジでの常時稼働を前提にしたときに、バッテリー寿命とシリコン面積の双方に直接関わる指標である。
メモリ壁を突破するHBMとSamsung IGZOの取り組み
SamsungのCTO、Jaihyuk SongはHBMにおけるハイブリッドボンディングの将来像を提示した。ハイブリッドボンディングによって12層積層(12H)から16H、最終的には20H積層が可能になり、熱抵抗の低減と帯域幅の向上が両立できる見通しである。ただし、HBMへのハイブリッドボンディング導入の具体的なタイムラインは公表されなかった。
材料面での進展として、Songが挙げたのがIGZO(酸化インジウムガリウム亜鉛)垂直チャネルトランジスタのDRAMへの適用である。チャネルを酸化物半導体に切り替えることで、リーク電流(オフ電流)を数桁以上削減できる。これは3D DRAMにおいて最も厄介な問題の一つであるリフレッシュ時の電力消費を抑える上で有効な手段であり、強誘電体材料を組み合わせることで動作電圧の低減も可能になることが確認されているという。
同社は電力供給の観点でも革新を試みており、GPUのコアロジックの一部をHBMのベースダイに移すことで、高速化と電力効率の両立を図っている。NVIDIAとの間では、プラズマエッチングや熱・機械モデリングに物理インフォームドAIモデルを適用する共同開発も進めており、製造プロセスそのものへのAI活用が具体化しつつある。
エコシステム協調なしに成立しない次世代半導体
imecが過去40年かけて築いたビジネスモデルの根幹は、個々の企業が内製では難しい先端技術開発を、エコシステム全体で分担するという構造にある。Synopsysのシニアディレクターであり元imec研究員のGermain Fengerは、その価値について、imecでは多くの分野の専門家に囲まれており通常の企業にありがちなサイロ化が避けられる、他社の専門家との交流を通じて技術の進む方向を幅広く俯瞰できる、と語る。
Brewer ScienceのシニアテクノロジストDouglas Guerreroは、エコシステム協調の実利的な側面を指摘した。「将来の技術ノードへの早期アクセスにより、材料革新をGAA(Gate-All-Around)や3D統合などの新興デバイスアーキテクチャに早期から合わせ込むことが可能になる。共同R&Dは初期投資を削減し、技術リスクをパートナー間で分散させる」。
高NA EUV露光装置についてもimecは進展を開示している。ASMLからの高NA(開口数0.55)スキャナーをクリーンルームに初めて設置し、16nmピッチのラインアンドスペース(8nmライン幅)と8.7nmのチップ間スペーシング(チップ先端間距離)をすでに実証した。この数値は、次世代プロセスノードの量産移行が評価段階に入ったことを示している。
UMCの技術開発担当副社長Steven Hsuは、imecのiSiPP300プロセス(12インチシリコンフォトニクス向け)を活用して自社12インチシリコンフォトニクスプラットフォームの開発を加速している事例を共有した。同社は従来6インチ・8インチウェーハ主体でシリコンフォトニクスICを製造してきたが、AI向け高帯域光インターコネクトの需要拡大を受けて12インチへの移行を進めており、PDKの一般顧客向け公開を2027年に予定している。
ハードウェアが再び差別化要因になる理由
現在の半導体産業のスケーリング方程式を一つの式で表せば、imecの整理では次のようになる。
「鈍化したスケーリング + STCO(システム技術共同最適化)によるブースター = 目標スケーリング」
この式が示すのは、微細化だけでは次世代AIワークロードへの対応が難しくなった現状を、3D統合と異種統合によって補う戦略である。デバイス層では3D DRAMと3D NAND(メタルゲートとエアギャップ付き)、ロジック向けにはCMOS 2.0が適用され、パッケージ層ではウェーハ間・チップ間ハイブリッドボンディング、バックサイドPDN、TSVインターコネクトが組み合わされる。
こうした変化の結果として、フロンティアAIアルゴリズムを走らせる上でのハードウェア差異が拡大する。同じアルゴリズムでも、シリコンフォトニクスを使った光インターコネクトを持つシステムと、電気的インターコネクトのみのシステムとでは、データ移動の帯域幅とエネルギー効率が大きく異なる。アルゴリズムがハードウェアに特化して最適化されるほど、汎用ハードウェアとの性能差は広がる構造になっている。
Fengerの言う通り、複雑化が深まるほど外部との連携なしには先端開発が成り立たなくなる。設計からプロセス開発、製造、先端パッケージングにわたってサプライチェーン全体のアライメントが強まる中、2030年代の半導体産業は、技術力だけでなくエコシステムの連携密度そのものが競争の軸になりつつある。


