
AMDは、同社のFinancial Analyst Day 2025において、AIおよびHPC市場における次世代の戦略的製品となるInstinct MI400シリーズ、および将来のMI500シリーズのロードマップを公開した。2026年に投入が予定されるInstinct MI400シリーズは、新アーキテクチャ「CDNA 5」と次世代メモリ「HBM4」を搭載し、現在AIアクセラレータ市場で支配的な地位を占めるNVIDIAの次世代プラットフォーム「Vera Rubin」に直接対抗する。
AI市場の勢力図を塗り替えるAMDの年間ケイデンス戦略
現在のAIアクセラレータ市場は、NVIDIAがCUDAエコシステムを武器に圧倒的なシェアを維持している。しかし、AMDはInstinct MI300シリーズで着実に市場での存在感を高めており、ソフトウェアエコシステムであるROCmの機能拡充とWindows対応などを通じて、開発者の支持を着実に集めつつある。
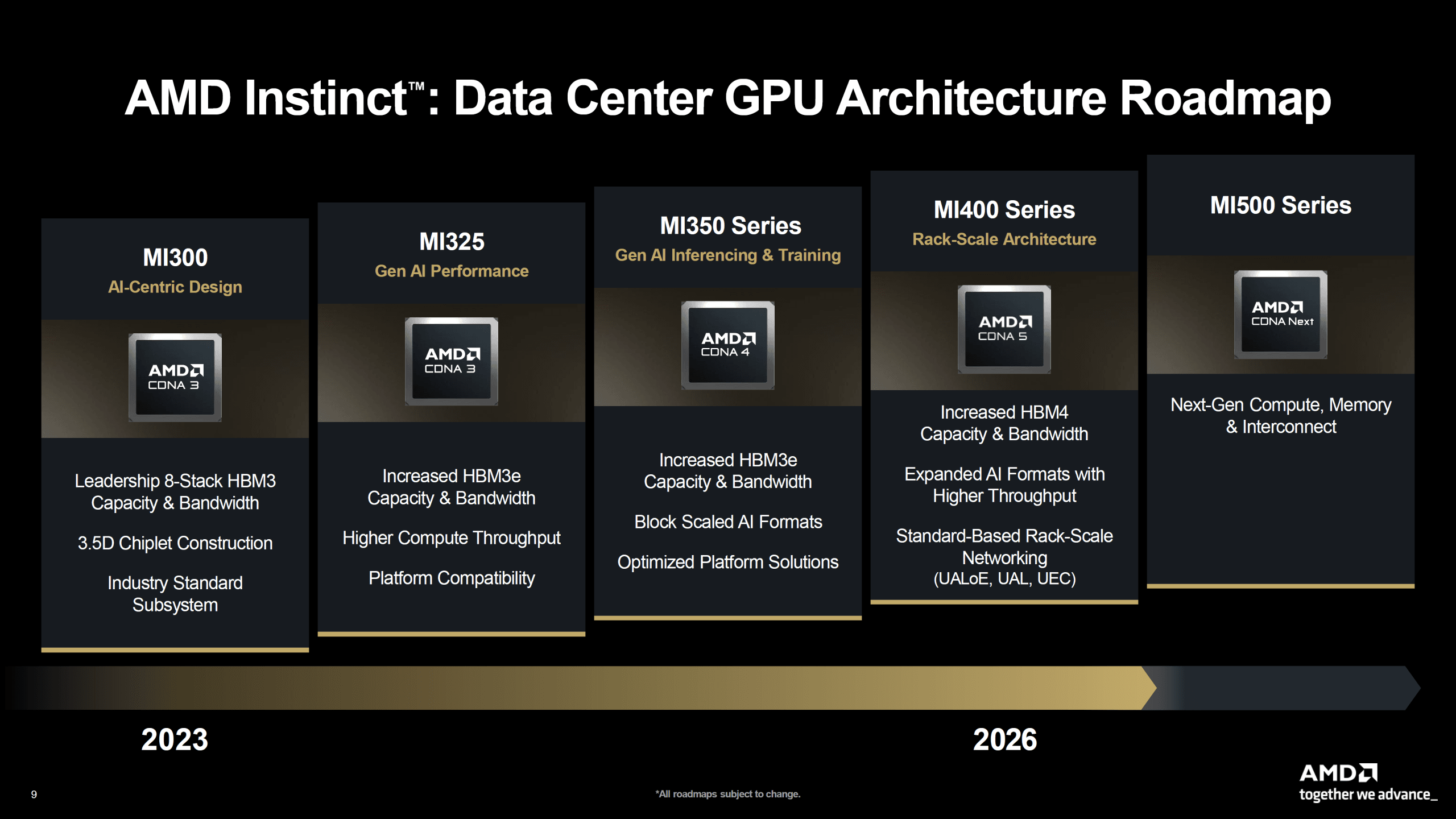
今回AMDが強調したのは、「年間ケイデンス(Annual Cadence)」、すなわち毎年新世代の製品を市場に投入する戦略だ。これは、NVIDIAが標準モデルと高性能版(例:BlackwellとBlackwell Ultra)を投入する製品サイクルに追随、あるいは先行することで、顧客に対して常に最新・最良の選択肢を提供し続けるという強い意志の表れである。2026年のMI400シリーズ、そして2027年のMI500シリーズという明確なロードマップは、AMDがこの競争に長期的にコミットすることを示すものであり、市場の健全な競争を促進する上で極めて重要な意味を持つ。
Instinct MI400シリーズのアーキテクチャ分析
Instinct MI400シリーズの性能を支えるのは、アーキテクチャ、メモリ、インターコネクトという三つの柱における抜本的な革新である。
新アーキテクチャ「CDNA 5」の核心:低精度演算の最大効率化
MI400シリーズは、AMDのデータセンター向けGPUアーキテクチャの第5世代となる「CDNA 5 (Compute DNA 5)」を基盤とする。CDNAアーキテクチャは、初代から一貫して行列演算性能の強化に注力してきた。CDNA 5では、その方向性がさらに先鋭化されている。

AMDが公表したスペックで最も注目すべきは、40 PFLOPSのFP4演算性能と20 PFLOPSのFP8演算性能である。これは現行世代のMI350シリーズの2倍に相当する数値であり、アーキテクチャレベルで低精度データフォーマットの処理能力が大幅に強化されたことを示唆している。
- FP8 (8-bit Floating Point): 主にAIモデルの学習(トレーニング)において、FP16やBF16と比較してメモリ使用量とデータ転送量を半減させ、演算スループットを向上させるために利用される。
- FP4 (4-bit Floating Point): 主にAIモデルの推論(インファレンス)で用いられる。モデルの量子化により、メモリフットプリントを劇的に削減し、推論速度を最大化する。特に大規模言語モデル(LLM)のエッジ展開や、データセンターでのサービスコスト削減に不可欠な技術である。
CDNA 5は、これらの低精度フォーマットを効率的に処理するための専用演算ユニットを大幅に増強、あるいはデータパスを最適化した設計であると推察される。これは、現代のAIワークロードが学習から推論へと広がる中で、あらゆる局面で最高のパフォーマンスを提供しようとする設計思想の表れである。
メモリ階層のブレークスルー:HBM4の採用がもたらす変革
AIアクセラレータの性能は、演算能力(FLOPs)だけでなく、その演算器にどれだけ速くデータを供給できるか、すなわちメモリ帯域によって大きく左右される。MI400シリーズは、業界に先駆けて次世代の高帯域幅メモリ「HBM4」を採用することで、このボトルネックを解消しようとしている。
- 容量の飛躍 (288GB → 432GB): MI350シリーズの288GB (HBM3E) から、MI450シリーズでは432GB (HBM4) へと1.5倍に増加する。この大容量化は、パラメータ数が数千億から兆に達する巨大なLLMを扱う上で決定的な意味を持つ。より大きなモデルやその一部を単一のアクセラレータ内に収めることが可能となり、複数のGPU間で発生するデータ通信のオーバーヘッドを削減する。これにより、学習時間の短縮と推論時のレイテンシ低減が期待できる。
- 帯域の爆発 (8TB/s → 19.6TB/s): メモリ帯域は、MI350の8TB/sから19.6TB/sへと2.4倍以上に跳ね上がる。この圧倒的なデータ供給能力は、CDNA 5アーキテクチャが持つ膨大な演算能力を余すことなく引き出すための生命線である。メモリ帯域が演算性能に見合っていなければ、演算器はデータを待つアイドル状態に陥り、実効性能は頭打ちとなる。19.6TB/sという帯域は、40 PFLOPSという演算性能を支える上で、極めて合理的な設計目標と言える。
さらに、MI400シリーズはパッケージング技術を従来のCoWoS-SからCoWoS-L (Local Silicon Interconnect) へ移行するという。これは、より大規模なシリコンインターポーザを可能にし、HBM4スタックのような多数のチップレットを効率的に接続するための技術的選択であり、性能と歩留まりの両立を目指した結果と考えられる。
スケール性能を司るインターコネクト戦略
単一GPUの性能向上だけでなく、数百、数千のGPUを接続して単一の巨大な計算リソースとして利用する「スケールアウト」性能も重要である。AMDはMI400シリーズにおいて、GPUあたり300 GB/sのスケールアウト帯域を提供すると発表した。
注目すべきは、AMDが標準ベースのラック規模ネットワーキング(UALoE, UAL, UEC) を推進している点である。これは、特定のベンダーにロックインされるNVIDIAのNVLinkやInfiniBandといったプロプライエタリな技術とは対照的である。AMDは、オープンな標準規格を採用することで、顧客がより柔軟に、かつコスト効率良く大規模システムを構築できるという価値を提案している。これは、多様なハードウェアが混在する次世代データセンターを見据えた、長期的なエコシステム戦略の一環と分析できる。
パフォーマンス分析:AMD Instinct MI450 対 NVIDIA Vera Rubin
AMDは、MI450シリーズの性能をNVIDIAの次世代プラットフォーム「Vera Rubin」と直接比較する強気な姿勢を見せている。
| 性能指標 | AMD Instinct MI450シリーズ vs NVIDIA Vera Rubin | 技術的考察 |
|---|---|---|
| メモリ容量 | 1.5倍 | 432GBという容量は、現時点で公表されている競合の情報に対して明確な優位性を持つ。LLMの展開において大きなアドバンテージとなる可能性がある。 |
| メモリ帯域 | 同等 | 両者ともにHBM4を採用し、20TB/s近い帯域を目指していることを示唆。ボトルネック解消という点では互角の競争が予想される。 |
| FP4 / FP8 FLOPs | 同等 | 演算性能でNVIDIAに並ぶという野心的な目標。アーキテクチャの効率、クロック周波数、消費電力が鍵となる。 |
| スケールアップ帯域 | 同等 | ノード内(サーバー内)のGPU間接続性能。AMDは3.6TB/sの帯域を主張しており、NVIDIAのNVLinkスイッチ技術と同等の性能を目指す。 |
| スケールアウト帯域 | 1.5倍 | ノード間の接続性能。AMDが標準ベースのネットワーキングで、より高い帯域効率を実現できると主張している点に注目が必要。 |
この比較は、AMDが性能のあらゆる側面でNVIDIAに追いつき、メモリ容量とスケールアウト性能では凌駕しようとしていることを明確に示している。ただし、これらの数値は両社ともに将来の製品に対する目標値であり、実際のアプリケーションにおける実効性能は、コンパイラやライブラリといったソフトウェアスタックの成熟度に大きく依存することを忘れてはならない。
戦略的ポートフォリオ:MI455XとMI430Xの狙い
AMDはMI400シリーズを、市場ニーズに合わせて最適化した2つの製品ラインで展開する。
- Instinct MI455X: 「AIトレーニング&インファレンス」に特化したモデル。おそらく、HPCで重要となるFP64(64-bit 浮動小数点)演算ユニットなどを削減、あるいは簡素化することで、シリコン面積をAI関連の演算器に集中させ、電力効率とコストパフォーマンスを最大化する設計と推察される。主なターゲットは、大規模なAIモデルを運用するハイパースケーラーやAI研究機関である。
- Instinct MI430X: 「HPC & ソブリンAI」をターゲットとするモデル。こちらはハードウェアベースのFP64性能を維持し、従来の科学技術計算市場の需要に応える。特筆すべきは「ソブリンAI(Sovereign AI)」というキーワードである。これは、各国の政府や公的機関が、安全保障やデータ主権の観点から、国外のクラウドサービスに依存せず自国内にAIインフラを構築する動きを指す。MI430Xは、こうした国家主導のプロジェクトに最適なソリューションとして位置づけられており、地政学的トレンドを的確に捉えた戦略的な製品である。
この2本立ての戦略により、AMDは成長著しいAI市場と、伝統的に重要であるHPC市場の両方を効果的にカバーすることが可能となる。
未来への布石:MI500と加速する開発競争
AMDはさらにその先を見据え、2027年に「Instinct MI500」シリーズを投入する計画を明らかにした。具体的なスペックは未公開ながら、「次世代のコンピュート、メモリ、インターコネクト」を搭載し、MI400から「次の大きな飛躍(Next Big Leap)」を実現するとしている。
MI500では、TSMCの次世代プロセスノード(例えばN2P)の採用、HBM4のさらなる高速化、そしてCDNAアーキテクチャの次なる進化が期待される。AMDが年間ケイデンスを維持し、このような野心的なロードマップを提示し続けることは、市場全体に健全な競争と技術革新をもたらすだろう。
AI覇権をめぐる競争は新たな次元へ
AMDが発表したInstinct MI400およびMI500のロードマップは、単なる新製品の予告ではない。それは、NVIDIAの牙城を崩し、AIアクセラレータ市場における真の競争相手となるための明確な戦略宣言である。
Instinct MI400シリーズは、CDNA 5アーキテクチャによる低精度演算の強化、HBM4によるメモリボトルネックの解消、そしてオープンなインターコネクト戦略を武器に、スペック上ではNVIDIA Vera Rubinと互角以上に渡り合うポテンシャルを秘めている。特に、メモリ容量と製品ポートフォリオの戦略性は、特定のワークロードや市場セグメントにおいてAMDに有利に働く可能性がある。
ただし、この戦いの勝敗を決するのはハードウェアの性能だけではない。AMDにとって最大の課題であり、成功への鍵を握るのは、ソフトウェアエコシステム「ROCm」のさらなる成熟と普及である。開発者がCUDAからROCmへ容易に移行でき、安定したパフォーマンスを発揮できる環境が整備されて初めて、Instinctシリーズの真価が発揮される。
この熾烈な開発競争は、最終的にユーザーに多大な恩恵をもたらす。性能向上、価格の適正化、そして技術選択の自由度の拡大。AMDの挑戦が、AIインフラの未来をより豊かで多様なものにしていくことは間違いない。