
中国のAIスタートアップDeepSeekが、OpenAIのo1に匹敵する推論能力を持つ新しい大規模言語モデル(LLM)「R1」を発表した。同社の主張によれば、一部のベンチマークではo1を上回る性能を実現している。この記事では、このオープンソースモデルの概要とこれをユーザーがオンラインまたはローカルで利用する方法について解説する。
モデルの概要と技術的特徴
R1は、DeepSeek V3をベースに強化学習によって微調整された671Bパラメータのモデルだ。注目すべき特徴は、Chain-of-Thought(CoT)推論を活用していることにある。これは従来のLLMのように単純な回答を生成するのではなく、まず問題を「思考の連鎖」として分解し、推論過程で誤りや幻覚を修正してから最終的な回答を導き出す仕組みだ。
開発コストの面でも革新的だ。DeepSeek V3は2,048台のNVIDIA H800を使用し、約558万ドルで開発された。これは競合他社が数十億ドルを投じている現状と比較すると、驚くべき効率性を示している。
DeepSeek-R1の性能評価
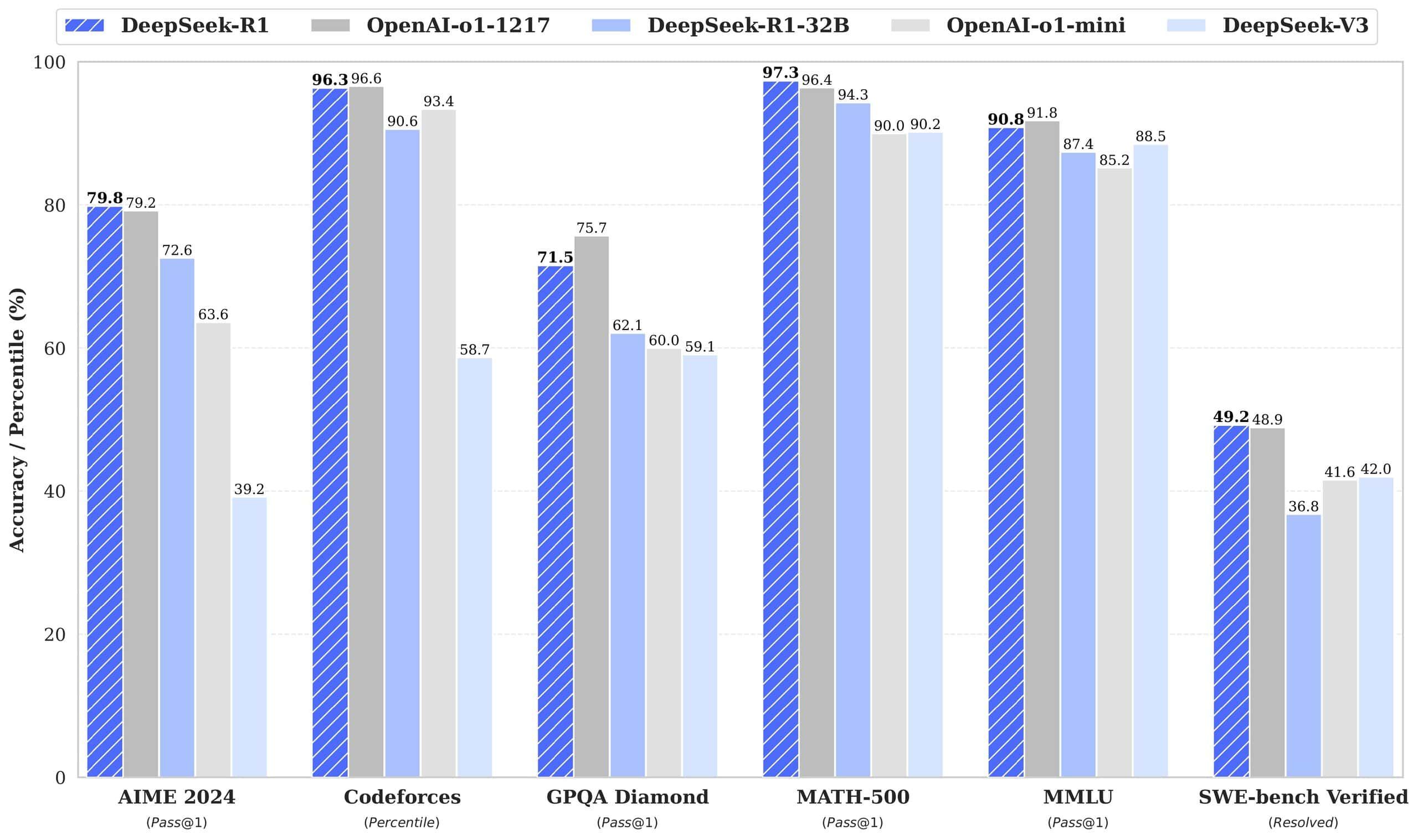
実際のテストでは、以下のような結果が得られている:
- 文字カウント課題(「strawberry」のRの数を数える等)で高い精度を実現
- 数学的推論において、基本的な計算から代数的な問題解決まで対応可能
- 空間認識や計画立案のパズルでも、一定の成功率を示す
ただし、これらの性能は完全に安定しているわけではない。同じ質問に対して異なる回答をすることもあり、特に小規模なモデルではその傾向が顕著だ。
DeepSeek-R1の詳細な導入ガイド
DeepSeek-R1の利用については、完全版が公式サイトから利用できる。メールアドレスや電話番号などを用いたユーザー登録もしくはGoogleアカウントから利用登録が可能だ。
利用登録が済めばChatGPTライクなチャット画面が表示される。ここからモデル「DeepThink(R1)」を選択すれば、DeepSeek-R1の利用が可能だ。
また、ローカルでの利用も可能だ。DeepSeek-R1の導入は、適切な環境さえ整えれば比較的簡単なプロセスで実現できる。
必要な環境要件
ハードウェア要件
- GPU:NVIDIA/AMD対応カード(最低8GB VRAM)
- Appleシリコン搭載Mac:最低16GB RAM
- ストレージ:モデルサイズに応じて10-50GB程度の空き容量
ソフトウェア要件
- Linux/Windows/macOS
- Docker Engine または Docker Desktop
- CUDA Toolkit(NVIDIAカード使用時)
インストール手順
1. Ollamaの導入
導入の第一歩は、Ollamaのインストールだ。Linuxユーザーの場合は、ターミナルで一行のコマンドを実行するだけで良い:
# Linux
curl -fsSL https://ollama.com/install.sh | shWindowsやmacOSユーザーは、ollama.comからインストーラーをダウンロードして実行する。
2. モデルのダウンロード
Ollamaのインストールが完了したら、次はモデルのダウンロードに移る。最も軽量な8Bモデルは以下のコマンドでダウンロードできる:
# 8Bモデル(4.9GB)
ollama pull deepseek-r1:8b
# より大きなモデル
ollama pull deepseek-r1:14b # 14Bパラメータ
ollama pull deepseek-r1:32b # 32Bパラメータ
ollama pull deepseek-r1:70b # 70Bパラメータこのモデルは4.9GBのサイズで、8GB VRAMのGPUでも快適に動作する。より高性能なハードウェアを持っている場合は、14B、32B、70Bといった大きなモデルを選択することも可能だ。
# より大きなモデル
- ollama pull deepseek-r1:14b # 14Bパラメータ
- ollama pull deepseek-r1:32b # 32Bパラメータ
- ollama pull deepseek-r1:70b # 70Bパラメータ
3. Open WebUIのセットアップ
より使いやすいインターフェースが必要な場合は、Open WebUIの導入を検討すると良い。これはDockerを使用して簡単にデプロイできる:
# Docker コンテナの起動
docker run -d --network=host \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:mainモデル使用時の最適化設定
セットアップ後は、ブラウザでhttp://localhost:8080にアクセスしてWebインターフェースを利用できる。
パフォーマンスについて注意すべき点は、R1がChain-of-Thought推論を採用しているため、通常のLLMと比べて処理時間が約2.6倍になることだ。これは、モデルが「思考」のプロセスを経て回答を生成するためである。質問の複雑さによっては、回答生成に数分かかることもある。
メモリ使用量を抑えるために、モデルの量子化を活用できる。例えば32Bモデルは4bit量子化を適用することで、24GB VRAMでも動作可能だ。ただし、量子化はモデルの精度とのトレードオフとなる点に注意が必要である。
トラブルシューティングとしては、GPUメモリ不足やOpen WebUIの接続エラーが一般的だ。前者は小さなモデルの使用や量子化レベルの調整で、後者はポート開放やDockerネットワーク設定の確認で対応できる。また、システムリソースの監視と最適化も、安定した運用のために重要となる。
中国特有の制約
CoT推論の採用により、従来のLLMと比較して処理時間が長くなる傾向がある。これは「思考」のプロセスが追加されることで、より多くのトークン生成が必要になるためだ。また、中国のモデルに共通する特徴として、「天安門事件」等の特定の政治的トピックに関する制限が組み込まれている点には注意が必要だ。