
数週間、あるいは数ヶ月にわたる膨大な計算の末に、ようやく得られるはずだったAIモデルの学習成果。そのすべてが、肉眼では決して見ることのできない、たった一つの半導体コアの「沈黙のエラー」によって水泡に帰する――。これは、現代のAI開発が直面する、悪夢のようなシナリオだ。
Teslaは、この悪夢を現実のものにしないため、自社開発のAIスーパーコンピューター「Dojo」のために、極めて高度な欠陥コア発見ツール「Stress」を開発・運用していることを明らかにした。これは、数百万ものコアを持つ巨大なコンピューターの心臓部を、稼働させたまま “外科手術”を施すかのような驚くべき技術なのだ。
AI開発の根幹を揺るがす「サイレントデータ破損」という亡霊
私たちが日常的に使うPCやスマートフォンでさえ、内部のプロセッサーは稀に計算ミスを犯すことがある。その多くは即座に検出・修正されるが、最も厄介なのが「サイレントデータ破損(Silent Data Corruption, SDC)」と呼ばれる現象だ。これは、計算エラーが発生したにもかかわらず、システムが何のエラーも警告も発することなく、間違ったデータを正しいものとして処理し続けてしまう不具合を指す。
通常、この種のSDCが致命的な問題を引き起こすことは稀だ。しかし、TeslaのDojoのような、AIの学習に特化した超大規模スーパーコンピューターの世界では話が全く異なる。
Teslaによれば、Dojoのシステム内でたった一つのコアがSDCを引き起こすだけで、「数週間かかるAIトレーニングを不正確なものにしたり、モデルの収束を遅らせたりする可能性がある」という。学習が完了した後に、その結果がSDCによって汚染されていたかどうかを特定することは「事実上不可能」だ。これは、AI開発における時間と計算資源という、最も貴重な資産を根底から覆しかねない、まさに亡霊のような脅威なのである。
Dojoの基本単位である「Training Tile」は、TSMCの先進的なパッケージング技術「InFO_SoW」を用いて、300mmウェハー上に354個のコアを持つ「D1」チップを25個、合計8,850個ものコアを敷き詰めた巨大なプロセッサーだ。これを複数組み合わせたDojoクラスタは、文字通り数百万のコアで構成される。このスケールでは、製造上の欠陥や経年劣化によるSDCの発生は、確率的に避けられない現実なのだ。
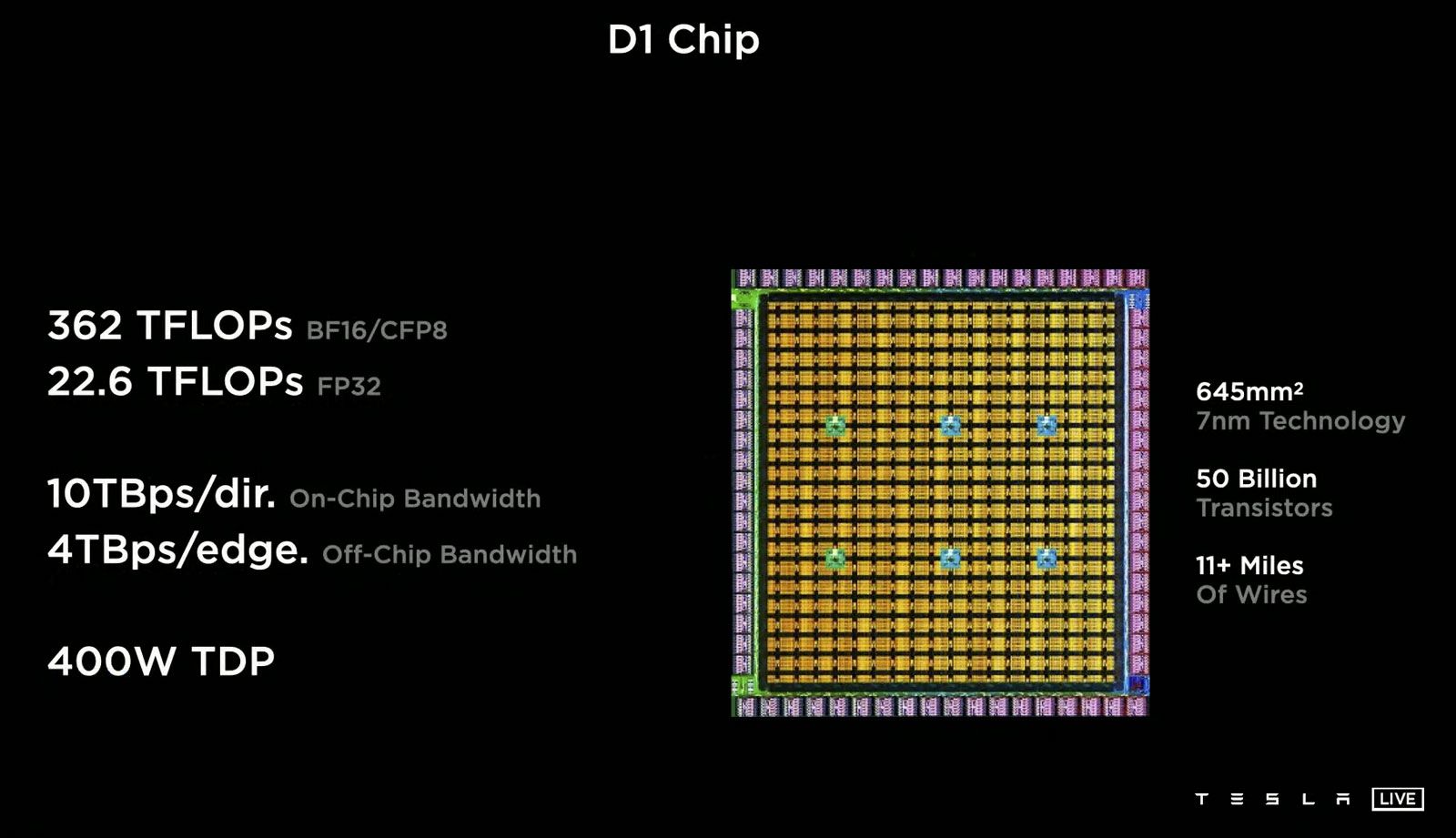
Dojoのための心臓外科手術:独自ツール「Stress」の進化の軌跡
この避けては通れない課題に対し、Teslaは「差分ファジング(Differential Fuzzing)」というテクニックを応用した独自ツール「Stress」を開発した。差分ファジングとは、基本的に同じ処理を複数のユニットに実行させ、その結果を比較することで、異なる振る舞いをする(つまり欠陥のある)ユニットを特定する手法だ。
しかし、8,850ものコアを持つDojoのTraining Tileで、これをいかに効率的に実行するか。Teslaが公開した情報からは、彼らのエンジニアリングチームによる試行錯誤とブレークスルーの物語が見て取れる。
ステップ1:ボトルネックとの遭遇
最初に試みられたのは、ホストコンピューターが生成したランダムな命令列(ペイロード)を、タイル内の全コアに配布し、実行させ、結果を回収・比較するという素直なアプローチだった。しかし、この方法はすぐに壁にぶつかる。Dojoタイルとホストコンピューター間の通信帯域がボトルネックとなり、テストに時間がかかりすぎてしまったのだ。理論上可能な性能よりも約1000倍も遅いという、実用に耐えないものだった。
ステップ2:発想の転換 – Dojoの力をDojoで試す
次なる一手は、まさに発想の転換だった。ホストに頼るのをやめ、Dojoのアーキテクチャの強みを最大限に活用したのだ。
- まず、8,850個のコアそれぞれに、異なるランダムな命令ペイロード(各0.5MB)を事前にアップロードする。
- テスト開始後、各コアは、タイル内にいる他のすべてのコアから順番にペイロードをダウンロードし、自身の空きメモリ空間で実行する。
- すべてのペイロードの実行が完了したら、各コアは自身が計算した結果のハッシュ値を保持する。
このアプローチの鍵は、ペイロードの交換がDojoタイル内部の超広帯域なネットワーク(10TB/s)で行われる点にある。低速なホスト-タイル間通信への依存を劇的に減らすことで、わずか数秒のうちに、タイル全体で合計4.4ギガバイトもの命令を実行できるようになった。Teslaが「この段階で最初の欠陥ノードを検出し始めた」と述べているように、これが大きなブレークスルーとなった。
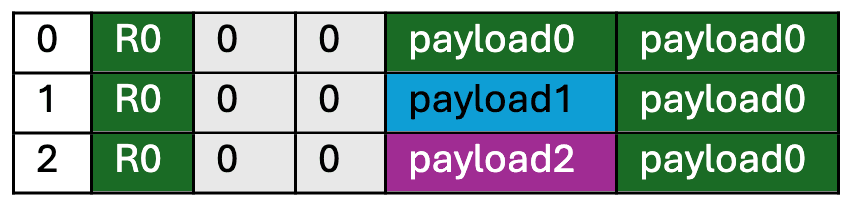
ステップ3:テストの深化と精度向上
効率化に成功したTeslaは、次にテストの「質」を高めるための改良を加えた。
- 状態のランダム化: 各ペイロードを実行する際に、前回の実行結果(レジスタやメモリの状態)をあえてクリアせず、そのまま次のペイロードを実行する。これにより、命令シーケンスのランダム性に加え、入力データ(実行時の状態)のランダム性も高まり、より稀な条件下でしか発生しないような微細なエラーを炙り出すことが可能になった。
- 「見えない欠陥」の可視化: 最も巧妙な改良が、特定の命令における欠陥の見逃しを防ぐ仕組みだ。例えば、MUL(乗算)命令に欠陥があっても、その計算結果が後続の命令ですぐに上書きされてしまうと、エラーは決して表面化しない。この問題に対し、数百命令ごとにレジスタの状態をXOR演算によって特定のSRAM領域に書き込む処理を挿入。これにより、たとえ直接使われなくても、計算結果の異常が最終的なハッシュ値に反映されるようになり、検出率が最大で10倍も向上したという。
この一連の進化は、Teslaが単に問題を解決するだけでなく、いかに深く、そして執拗にその本質を追求しているかを物語っている。
成果は絶大 – ハードウェアの欠陥から設計上のバグまで
この洗練された「Stress」ツールは、Dojoクラスタに展開され、目覚ましい成果を上げている。
- 多数の欠陥コアを発見: 稼働中のDojoシステムから多くの欠陥コアを特定し、無効化することに成功。その欠陥率は、同様の研究を発表しているGoogleやMetaの報告と同程度であり、Teslaのハードウェア品質と検証能力が業界トップレベルにあることを示唆している。
- 多様な欠陥の検出: 欠陥の検出にかかる時間は、数秒から数分で発見できるもの(1GB〜100GBの命令実行)がほとんどだが、中には数時間(1000GB以上の命令実行)を要する、非常に見つけにくい欠陥も存在する。
- ハードウェアに留まらない貢献: 「Stress」の功績は、単なる不良品の発見に留まらない。Teslaは、このツールによって「ソフトウェアで回避可能な、稀なコーナーケースの設計バグ」や、複数の低レベルソフトウェアのバグも発見したと報告している。これは、「Stress」がハードとソフトの両面にまたがるシステムの健全性を包括的に検証するプラットフォームとして機能していることを意味する。
特筆すべきは、このテストがDojoのコアをオフラインにすることなく、バックグラウンドで実行できる点だ。AIの学習を続けながら、継続的にシステムの健康診断を行い、問題が見つかったコアだけを切り離す。まさに究極のインフィールド・モニタリングと言えるだろう。
ウェハースケール時代の幕開け – Teslaの挑戦が示す未来
筆者が特に注目したいのは、このTeslaの取り組みが、今後のコンピューティング業界全体にとって持つ意味の大きさだ。
DojoやCerebras Systemsが開発するような「ウェハースケールプロセッサー」は、これまで複数のチップに分割して製造されていたものを、一枚のシリコンウェハー上に巨大な単一プロセッサーとして作り上げる技術だ。TSMCも、この種の技術が今後、より多くの企業に採用されていくとの見通しを示している。
コンピューティングの規模がこのように飛躍的に増大する時代において、個々のコンポーネントの信頼性をいかに担保し、システム全体として安定稼働させるかという問題は、避けては通れない最重要課題となる。Teslaの「Stress」は、その課題に対する一つの先進的な答えだ。
ハードウェア(Dojo)から、その上で動くソフトウェア、さらにはそれを検証するツール(Stress)まで、すべてを自社で開発するTeslaの「垂直統合」戦略の強みが、ここにも表れている。彼らは、自らの手で作り上げた複雑なシステムの「クセ」を誰よりも深く理解し、それに最適化された最高品質のメンテナンスツールをも作り上げてしまうのだ。
Teslaは今後、この「Stress」をハードウェアの経年劣化の研究や、半導体の生産前に設計を検証する「プリシリコン」の段階にも応用していく計画だという。この挑戦は、単なるTesla一社の品質管理の話ではない。AIとコンピューティングの未来が、いかにしてその「信頼性」という土台の上に築かれていくのか。その最前線を示す、非常に重要なマイルストーンなのである。
Source


