
サイエンス
極低温も特殊設備も不要。量子コンピュータとは異なる「Pコンピュータ」実現へ、東北大が世界初の快挙
0と1の間を揺らぐスピン素子を用いた次世代「確率コンピューター」。東北大と米国NISTは、これまで手作業の配線に頼っていた本技術を既存の半導体プロセスでシリコンチップ上へ完全統合することに成功した。巨大AIの電力問題を覆す、100万ビット規模の実用化に向けた画期的ブレイクスルーに迫る。
Topic
Generative AI
全 2,396 件 / 200 ページ
0と1の間を揺らぐスピン素子を用いた次世代「確率コンピューター」。東北大と米国NISTは、これまで手作業の配線に頼っていた本技術を既存の半導体プロセスでシリコンチップ上へ完全統合することに成功した。巨大AIの電力問題を覆す、100万ビット規模の実用化に向けた画期的ブレイクスルーに迫る。

NVIDIAがComputex 2026でARMベースSoC「RTX Spark」を発表。MediaTekと共同開発した20コアGrace CPU+Blackwell GPU+最大128GB統合メモリを1チップに統合し、初期Clangベンチマークでは43,149点を記録してApple M5を54%上回った。2026年秋にAsusやDellなど主要OEMから発売予定で、Windows ARMプレミアム市場への本格参入となる。

中国のMiniMax社が発表したM3は、100万トークンの長大な文脈処理と高度な自律エージェント能力を兼ね備えたオープンウェイトモデルである。独自の計算効率化技術により、低コストながら一部の主要な商用モデルを凌駕する性能を実現した。

Intelが次世代AI推論GPU「Crescent Island」で最大480GBのLPDDR5Xと350W空冷PCIe設計を示した。HBM搭載GPUの帯域競争とは別に、大容量・低消費電力・導入しやすさで推論市場を狙う。

NVIDIAが発表したCosmos 3は、テキスト・画像・動画・音声・アクションを単一モデルで処理する完全オープンのomnimodelだ。MoTアーキテクチャによる推論・生成の2タワー統合により物理AI訓練サイクルを数ヶ月から数日に短縮する可能性を持ち、Samsung・LGなど大手製造業の採用が始まった。物理AI基盤モデルのオープン化は、実装層での競争構造を変え、NVIDIA製GPU需要の次の成長エンジンとしても機能する戦略的な動きだ。

Intelは18Aプロセスを採用した次世代CPU「Xeon 6+」を発表した。新構造のトランジスタや裏面電力供給技術、高度な積層パッケージングにより、最大288コアの圧倒的な密度と電力効率を実現し、自律型AI時代の並列処理需要に応える。

NVIDIAが単なるGPUベンダーの枠を超え、PCの頭脳を再定義する。新SoC「RTX Spark」は、最大128GBの統合メモリでPCIeの限界を突破。自律型AIエージェントをローカルで駆動させ、IntelやAppleの牙城を崩すWindows on Armの全貌を徹底解説。

BloombergのMark Gurman氏が報じた最新情報によると、Apple初のスマートグラス(コード名N50)の発売が視覚AI(Computer Vision AI)の完成度不足を理由にlate 2027へ後ろ倒しとなった。「低遅延×低消費電力×精度」の3条件を小型チップで同時達成できないという技術的壁が、Metaとの競争ポジションとApple全体のウェアラブル戦略に影響を与えている。

中国科学院と人民解放軍が共同開発した「Air Target Agent System」は、LLMとAIエージェントを連携させ、衛星監視から標的判断までを人間の介在なしに自律実行する。Huawei Ascendチップ上で動作し、米国の輸出規制の射程外にあることが軍事AIの競争構図に新たな問いを投げかけている。
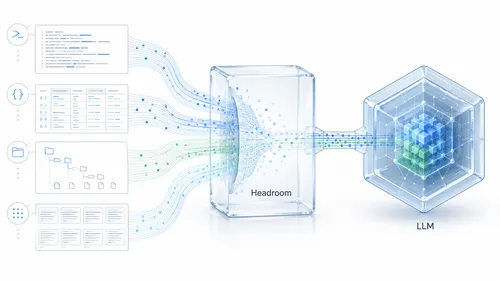
AIエージェントが読み込むログやMCP出力をローカルで圧縮し、不要な入力トークンを削減するHeadroomが注目を集めている。


AIサーバー向けHBM増産が進むほど、PC・スマホ向け汎用DRAMの供給が細るという逆説的な構造を、TrendForceが2027年グローバルメモリ市場1.28兆ドル予測の根拠として提示。エージェント型AIのKVキャッシュ需要急増と製造ラインの奪い合いが生む二重の価格高止まり圧力を解説。