
AIサーバーの電力消費が急増するなか、半導体産業は「もうチップを小さくするだけでは間に合わない」という壁に直面している。3nm世代から2nm世代にかけてSRAM(スタティックRAM)のスケーリング改善が数%にとどまり、微細化の物理的な限界が産業全体で意識されてきた。IBMはその問いに対し、平面の微細化をやめてトランジスタを縦に積む方法で答えを出した。
2026年6月25日、IBMは7アングストローム(7A)ノード——十進数で0.7nmに相当——の新チップアーキテクチャ「ナノスタック(NanoStack)」を発表した。IBM Research部長のJay Gambetta氏は「単なる漸進的な進歩ではなく、意味のある飛躍的前進だ」と述べ、従来の2nmチップとの比較で最大50%の性能向上または70%の大幅なエネルギー効率向上を実現したと発表した。
ナノスタックとは何か: トランジスタを縦に積む技術の仕組み
半導体の歴史を振り返ると、1959年のトランジスタ発明以来、チップは「2次元」で作られてきた。シリコンウェハーの表面に回路を彫り、その細かさを競う微細化がムーアの法則の実体だった。ナノスタックはその方向を変え、「2次元の面」を「3次元の積み重ね」に転換する。
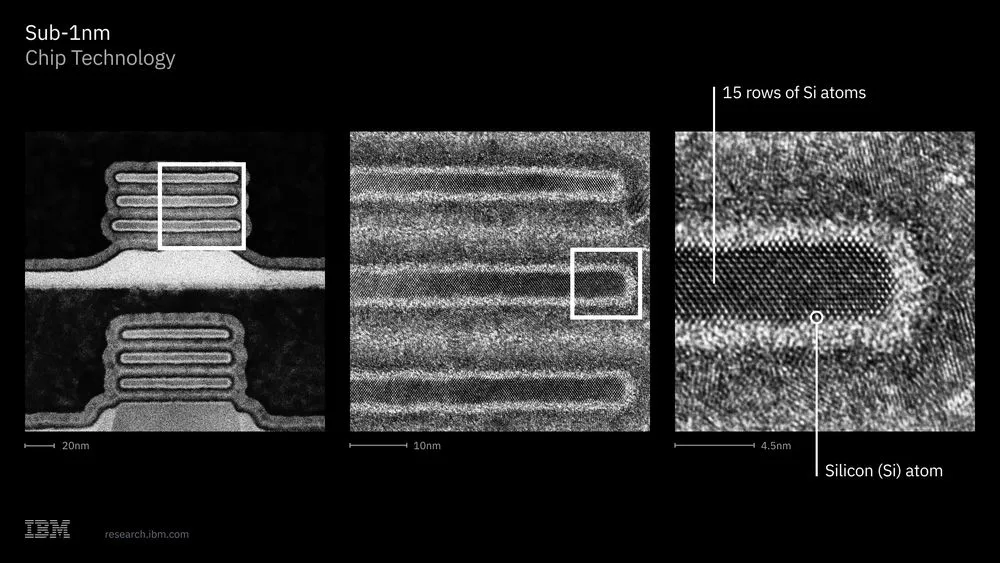
具体的な構造はCFET(Complementary FET)の逐次スタック方式(sequential CFET)と呼ばれる。NFETとPFETという2種類のトランジスタを垂直方向に積み上げ、かつ水平方向に互い違いにずらした「スタガー配置」をとる。各トランジスタはシリコン原子約15列分(厚さ5nm)のナノシートを3枚使い、9nmの間隔で配置される。この構造を実現するために、2枚のウェハーを30nm未満の超薄型誘電体ボンディングで接合する独自技術が採用されており、接合層の均一性は±1.5nm以内に抑えられている。
ここで一つ重要な注記が必要だ。「0.7nm」という数値は実際のトランジスタの物理サイズを意味しない。MIT Technology Reviewが指摘するように、このノード番号はマーケティング上の呼称であり、実際のトランジスタ間隔は約40nmで長期間ほぼ固定されている。「0.7nm」が示すのは設計世代の指標であり、文字通りの寸法ではない。半導体業界全体でこうした命名慣行が続いており、IBMのナノスタックも例外ではない。
この3次元積層の成果として、爪サイズのチップに約1000億個のトランジスタを集積できる。2nmチップの密度と比較して約2倍に相当する。IBMの研究成果は2025年のIEEE VLSIシンポジウム(京都開催)で「NanoStack Transistor Architecture for CMOS 7A Node and Beyond」として発表済みで、SRAMビットセルの40%面積削減は2026年のVLSIシンポジウムで追加発表された。
2nmとの差は何か: 50%の性能向上と70%省エネの根拠
密度が2倍になれば、同一のダイ面積でより多くの演算ユニットを配置できる。Gambetta氏が「エネルギーの比例的増大なしにコンピューティングが大幅に強力になる未来を指し示している」と述べたのはこの意味だ。演算性能を上げながら消費電力を据え置くのではなく、同等の演算量をより少ない電力で処理できる設計が可能になる。
SRAMの40%スケーリング改善はより踏み込んだ意義を持つ。SRAMはCPUやGPUのキャッシュメモリとして使われ、演算速度のボトルネックになりやすい部分だ。IBM半導体グローバルR&D担当副社長のHuiming Bu氏は「数十年ぶり」と表現するほどの改善幅だとしており、AIモデルの推論時に頻繁に参照するウェイトデータのアクセス速度に直結する改善だ。これらの数値は同社自身の2nmノードとの比較であり、現在流通する他社チップとの対比ではない。
AIインフラへの影響: SRAMと電力効率が変わる意味

AIのトレーニングと推論に使われるデータセンターは、世界全体の電力消費を押し上げる主要因の一つになった。大規模言語モデル(LLM)の学習では、数千枚のGPUが数週間から数ヶ月にわたり連続稼働する。この電力コストと冷却コストが、AIシステムの実用化を制約するボトルネックになっている。
ナノスタックが解決しようとしているのはこの問題の根幹だ。同一の演算量を70%少ない電力で処理できれば、データセンターの規模を変えずにAIの処理能力を大幅に引き上げられる。あるいは同等の性能を維持しながら設備コストを削減できる。イリノイ大学アーバナ・シャンペーン校の材料科学教授であるQing Cao氏はMIT Technology Reviewに対し「IBMの成果は、量産ラインでフルウェハー上にトランジスタをスタックする方法を実証した最初の事例だ」と評価している。
GPUやAI専用チップでは、演算器とメモリ間のデータ転送がボトルネックになる「メモリウォール(Memory Wall)」問題が深刻化している。SRAMキャッシュの面積を40%削減しながら同等の容量を確保できれば、より多くのキャッシュを同一ダイに搭載でき、演算器とデータの物理的な距離を縮められる。特にLLMの推論ではウェイトデータへのアクセスがGPU性能の上限を決めるため、この改善の効果は演算密度向上と並列して機能する。
なぜTSMCではなくIBM: 研究専業の強みと限界
TSMCやSamsungは年間数十兆円規模の製造設備を抱えているため、研究開発と量産コストの回収が常に綱引きをする。IBMにはその制約がない。現在はチップの設計・研究に特化し、製造はパートナーに委ねるビジネスモデルをとっているため、2nm世代の歩留まりを気にせず0.7nm世代の構造設計に全力を注げる。
量産の制約を外すことで、TSMC・Samsung・Intelが量産コスト、歩留まり、スケールを意識しながら進む領域で、IBMは純粋な技術探索ができる。2021年に世界初の2nmナノシートチップを発表し、その後TSMCとSamsungが独自に2nm量産を進めて業界標準化した経緯はこのパターンの典型例だ。
今回のナノスタックでも同じ図式が想定される。技術ライセンスを通じて収益化し、実際の製造は日本のRapidusとSamsungが担う。Huiming Bu氏は「今日、私たちはRapidusが日本で2nm製造能力を立ち上げる支援に注力している。ナノスタックの商業化については、まだ開示できない」と述べており、製造パートナーとの連携の詳細は現時点で明らかにされていない。Rapidusは2025年からテストウェハーを稼働させており、2027年後半には2nmナノシートの量産開始を目指している段階だ。
製造装置の面では、Lam Research、東京エレクトロン(TEL)、SCREEN Semiconductor Solutions、ASMLのHigh-NA EUV技術がナノスタック製造のパートナーとして名が挙がっており、装置サプライチェーンの構築は進んでいる。
5年後の量産化と競合の状況: TSMC・Intel・Huaweiとの比較
IBMは「最短5年以内」(2031年頃)の量産化を示している。TSMCは1.4nmの量産を2028年に予定しており、Intelの18A(1.8nm相当)は2026年6月時点でリスク生産段階にある。HuaweiはLogicFoldingと呼ばれる別ウェハーを後貼りするハイブリッド方式を発表している——いずれも量産前段階の技術が競い合う構図だ。
Intel・TSMC・Samsungが研究しているCFETの「モノリシック統合方式」に対し、IBMの逐次スタック方式(sequential CFET)は配線の独立制御が可能で、メモリ密度に有利とされる。一方で、2枚のウェハーを接合する製造プロセスは歩留まりの維持が難しく、量産段階での課題になりうる。IBMのロードマップは0.7nm(7A)から最終的に0.1nm(1アングストローム)までを設定しており、「10年間のスケーリングロードマップ」と明言している。
TechInsights副会長のDan Hutcheson氏はMIT Technology Reviewに対して「業界のロードマップにさらに10〜15年が加わった」と評価した。Huiming Bu氏は「何かが終わりに近づいているとき、それは進歩が止まるということではない。新しい方式が必要だということだ」と述べており、2次元微細化の後継として3次元積層に業界の焦点が移りつつある状況を端的に示した発言だ。
2021年の2nmと同じ起点に立った: 製造パートナーが次の鍵を握る

IBMが2021年に2nmナノシートを発表したとき、産業界が注目したのは「IBMが示した技術を誰が製造するか」という一点だった。TSMCとSamsungが独立して2nm量産体制を構築し、そのアーキテクチャが業界標準になるまでに約4〜5年かかった。ナノスタックは今、まったく同じ起点に立っている。
IBMのライセンス先として名が挙がるRapidusは2nm量産を2027年後半に目指しており、ナノスタックの量産ラインへの組み込みはその次の段階になる。実際の製品出荷は2030年代に入ってから——というシナリオが現実的だ。競合のTSMCも1.4nm量産を2028年に予定しており、3次元積層技術の採用は独自アーキテクチャで進んでいる。
IBMが「製造パラダイムを設計する企業」として機能するなら、ナノスタックの影響は量産化後に本格的に現れる。2021年の経緯が繰り返されるとすれば、TSMCやSamsungが独自のCFET設計を加速させ、ナノスタックの構造的アイデアが形を変えて2030年代のチップ標準に組み込まれていく可能性が高い。その分岐点はIBMではなく、製造側の判断にある。


