
AIの進化が指数関数的な成長を遂げる今、その性能を支える半導体の世界で、静かな、しかし決定的な主役交代劇が始まっている。これまで脚光を浴びてきたCPUやGPUに加え、今や「HBM(高帯域幅メモリ)」こそがAIコンピューティングの性能、ひいては国家の産業競争力をも左右する中核技術となりつつあるのだ。この潮流をいち早く読み解き、未来の覇権を握るべく、韓国科学技術院(KAIST)は2040年までを見据えた驚くべきHBMロードマップを提示した。本記事では、このKAISTによるHBM4からHBM8に至る次世代HBMの進化の予測をご紹介していく。
AI時代が求めるHBMの進化:3つのメガトレンド
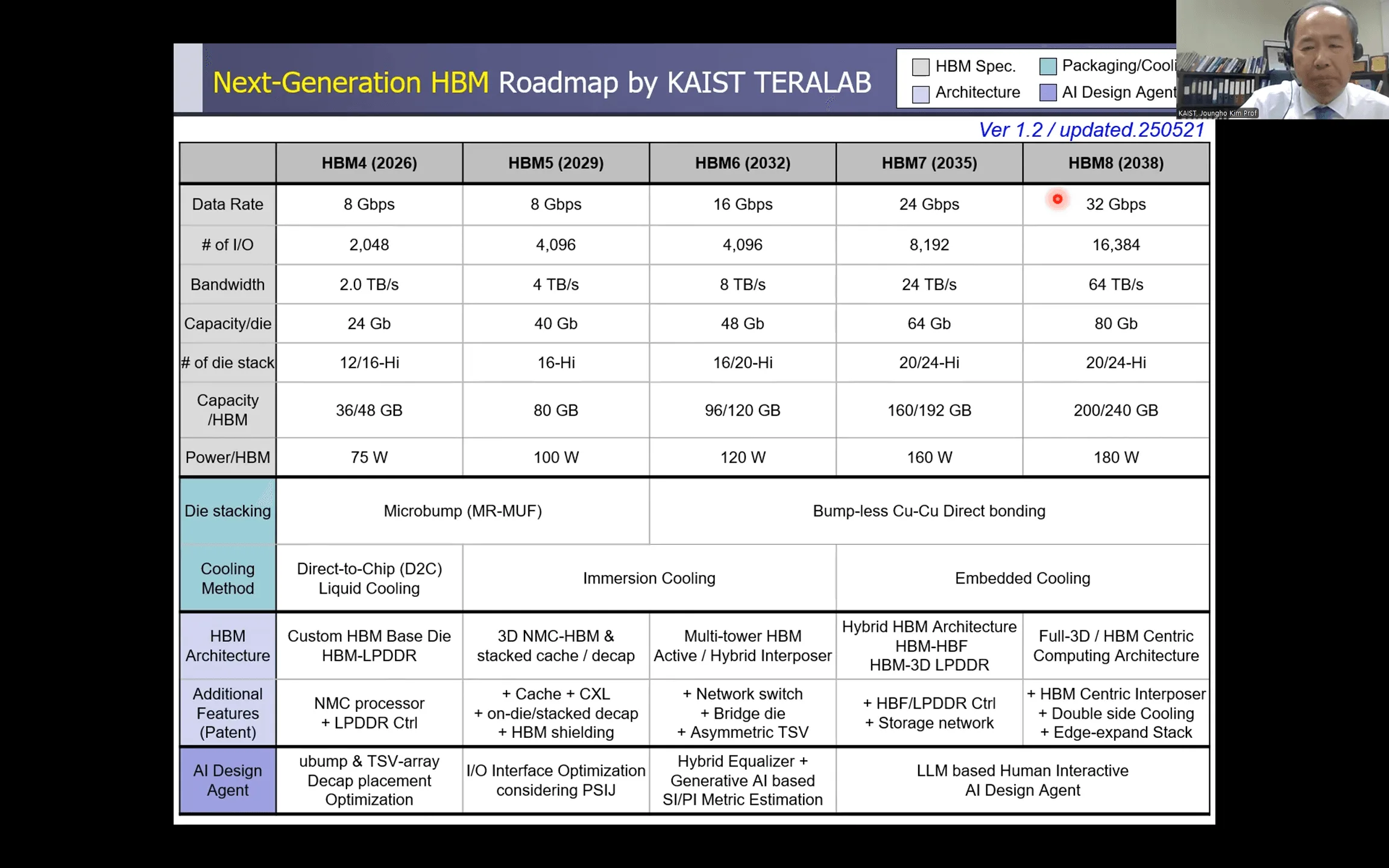
次世代HBMの進化は、これまでのようなスペックの向上だけには留まらないようだ。その進化は、AIが求める本質的な要求に応えるための、3つの明確な方向性を持っている。
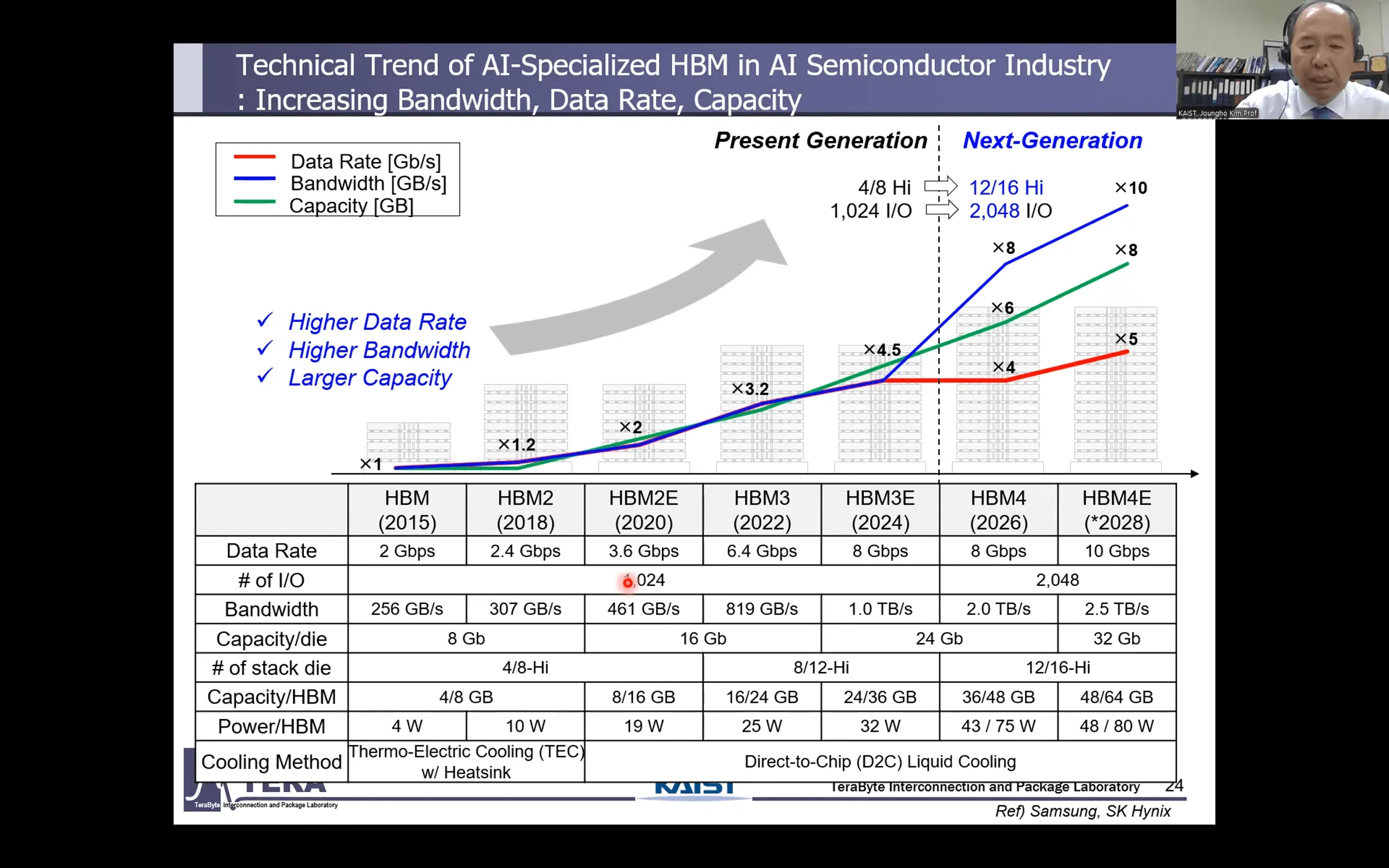
- 圧倒的な帯域幅と容量: 大規模言語モデル(LLM)のパラメータ数は爆発的に増大しており、これを処理するためには、桁違いのデータ転送速度(帯域幅)と記憶容量が不可欠である。HBM8では、帯域幅は1スタックあたり64TB/s、容量は240GBに達すると予測されている。
- GPUとの境界融解(ニアメモリコンピューティング): GPUとメモリ間のデータ移動は、深刻なボトルネック(フォン・ノイマン・ボトルネック)となっている。この壁を壊すため、HBM自体にデータ圧縮や一部の演算機能を持たせ、GPUの負荷を軽減する「ニアメモリコンピューティング」が本格化する。
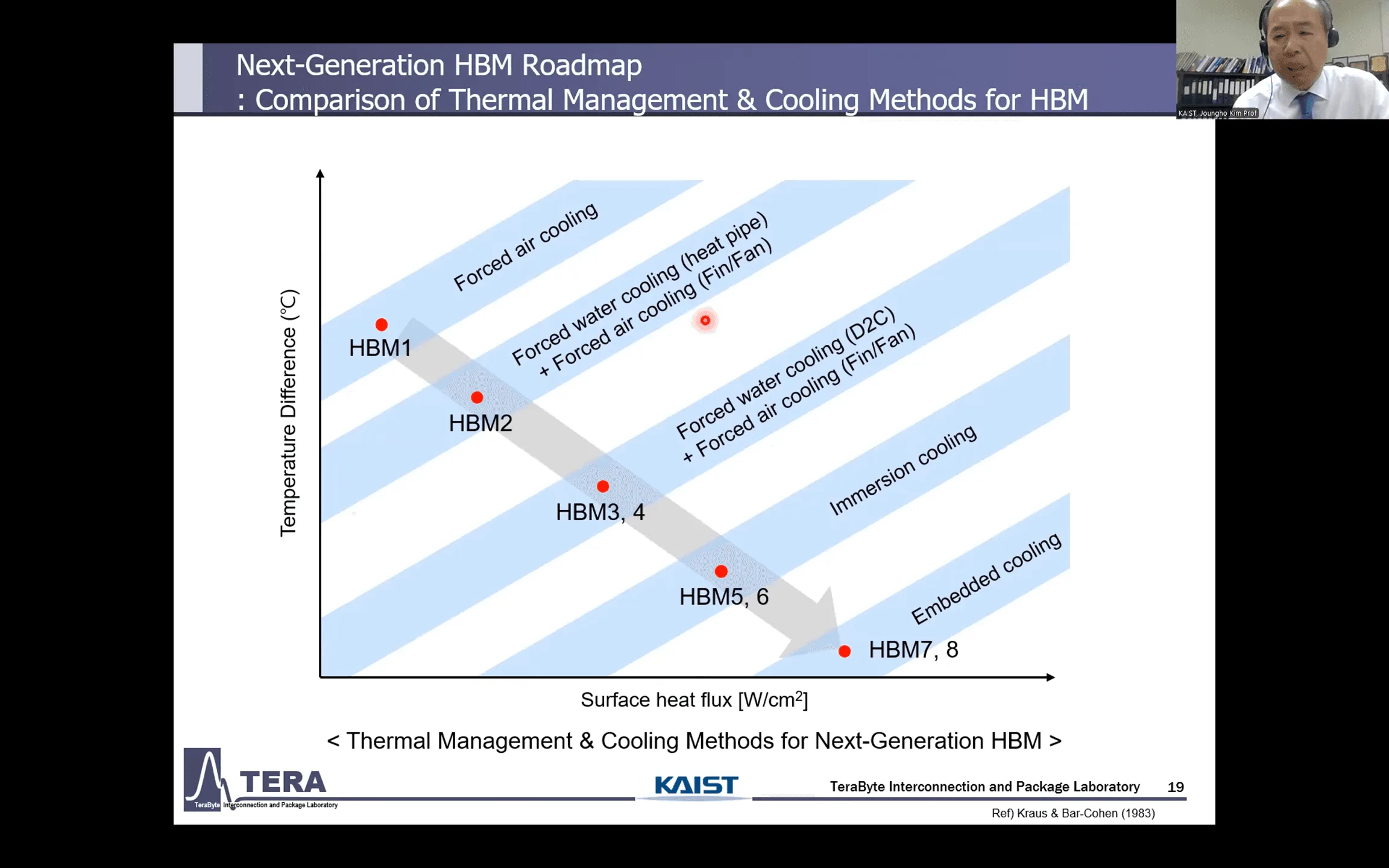
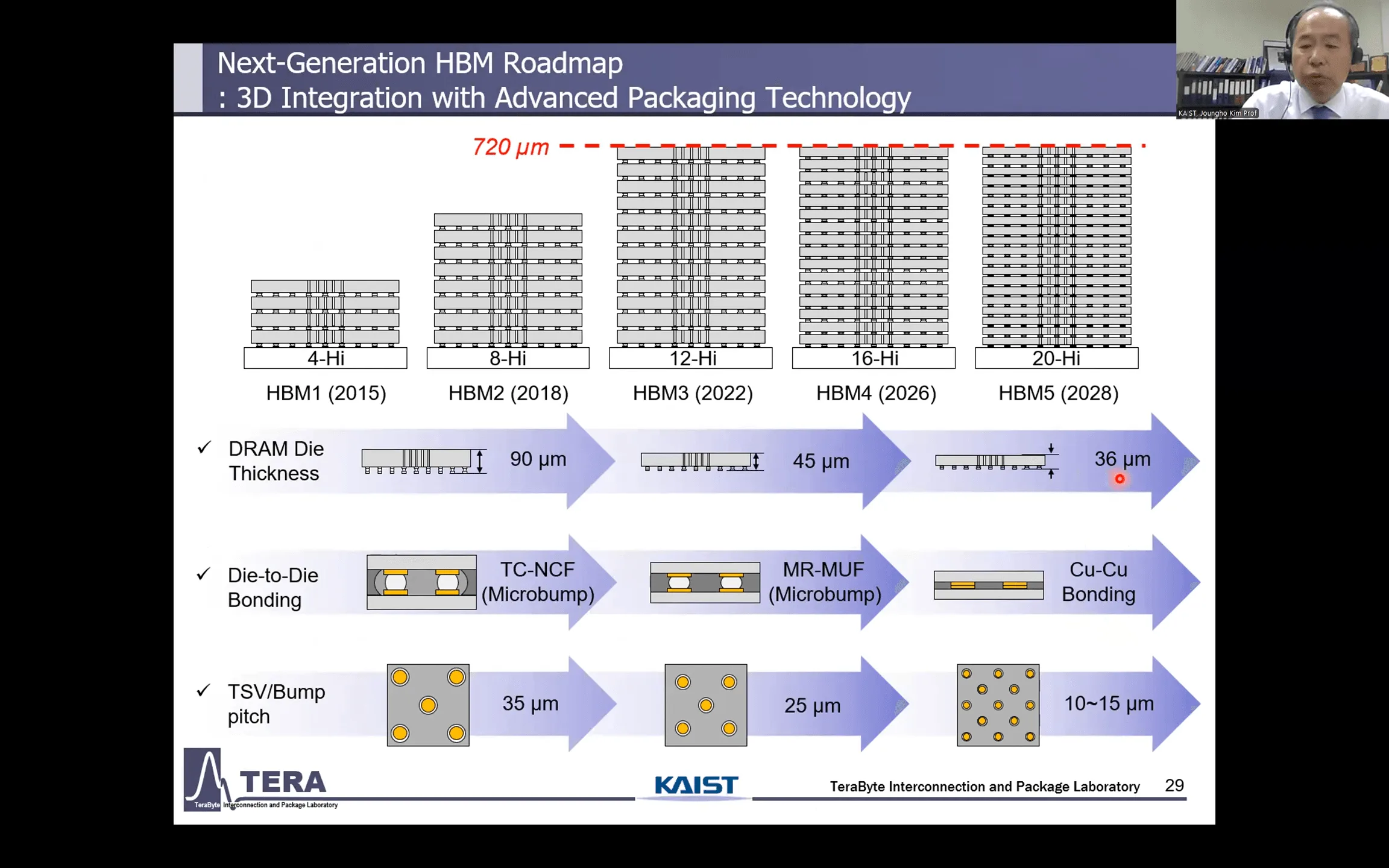
- 物理法則への挑戦(冷却とパッケージング): 高性能化は、凄まじい発熱との戦いでもある。空冷から液冷、そして液体に直接浸す「液浸冷却」、さらにはチップ内部に冷却水路を設ける「埋め込み型冷却」へと、冷却技術の革新がHBMの進化を支える。同時に、積層技術も限界に挑み、銅と銅を直接接合する技術や、シリコンに代わる「ガラスインターポーザ」が導入される。
この3つのメガトレンドを軸に、HBM4からHBM8までの具体的な進化の道のりを追っていこう。
HBM4 (2025年〜):システム半導体への第一歩、「カスタムベースダイ」の衝撃
HBM4は、HBMの歴史における最初の、そして最も重要な転換点となるだろう。その核心は「カスタムベースダイ」の導入にある。これは、HBMの最下層にある制御用のロジックダイを、NVIDIAやAMDといった顧客の要求に応じてカスタマイズし、GPUの機能の一部を搭載する試みだ。
- データレート: 8 Gbps (HBM4) / 10 Gbps (HBM4e)
- I/O数: 2048-bit(従来の2倍)
- 帯域幅/スタック: 2.0 TB/s (HBM4) / 2.5 TB/s (HBM4e)
- 容量/スタック: 36GB (12-Hi) / 48GB (16-Hi)
- 冷却: Direct-To-Chip (D2C) 液冷
これにより、HBMは単なる受動的なメモリ部品から、データ圧縮やエラー訂正、メモリトラフィック制御といった機能を持つ能動的な「システム半導体」へと進化を始める。NVIDIAの次世代GPU「Rubin」(2026年登場予定)やAMDの「Instinct MI400」は、このHBM4を採用し、メモリとプロセッサの境界線を曖昧にしていく最初の製品群となる。これは、HBMが汎用品から、顧客ごとに最適化された高付加価値製品へと変貌する時代の幕開けを意味する。
HBM5 (〜2029年):沸騰する熱を制する「液浸冷却」と設計思想の革命
HBM5世代では、さらに高まる性能要求と、それに伴う熱問題が技術革新を加速させる。ベースダイの発熱が限界に近づく中、設計思想そのものに大きな変革が求められる。
- データレート: 8 Gbps
- I/O数: 4096-bit
- 帯域幅/スタック: 4.0 TB/s
- 容量/スタック: 80GB (16-Hi)
- 冷却: 液浸冷却(Immersion Cooling)、サーマルビア(TTV)
HBM5の最大の挑戦は冷却だ。従来のD2C液冷では追いつかず、半導体チップ全体を冷却液に直接浸す「液浸冷却」が本格的に導入されると予測されている。さらに、演算機能の一部をHBMスタックの最上部に配置し、ヒートシンクで直接冷却する「ニアメモリコンピューティング」のアーキテクチャも検討されている。

この世代からは、信号だけでなく熱を効率的に伝導する「サーマルビア(TSV)」の設計が極めて重要になる。また、IO密度を高め、熱抵抗を下げるために、バンプを使わずに銅同士を直接接合する「カッパートゥカッパー(Cu-to-Cu)ダイレクトボンディング」が必須となるだろう。NVIDIAの「Feynman」アーキテクチャ(2028〜2029年)は、このHBM5を採用する最初のGPUになると見られている。
HBM6 (〜2032年):スケーリングの限界を超える「マルチタワー構造」と「ガラスインターポーザ」
HBM6は、物理的な実装面積の限界を打ち破るため、パッケージング技術に革命をもたらす。
- データレート: 16 Gbps
- I/O数: 4096-bit
- 帯域幅/スタック: 8.0 TB/s
- 容量/スタック: 96GB (16-Hi) / 120GB (20-Hi)
- パッケージング: Bump-less Cu-Cu Direct Bonding
- インターポーザ: アクティブ/ハイブリッド(シリコン+ガラス)インターポーザ
シリコンインターポーザの面積拡大が限界に達する中、HBM6では2つの画期的なアプローチが提案されている。一つは、1つのベースダイ上に複数のDRAMスタックを積み上げる「マルチタワーHBM」だ。例えば4つのタワーを配置する「クアッドタワーHBM」は、容量と帯域幅を飛躍的に向上させる。
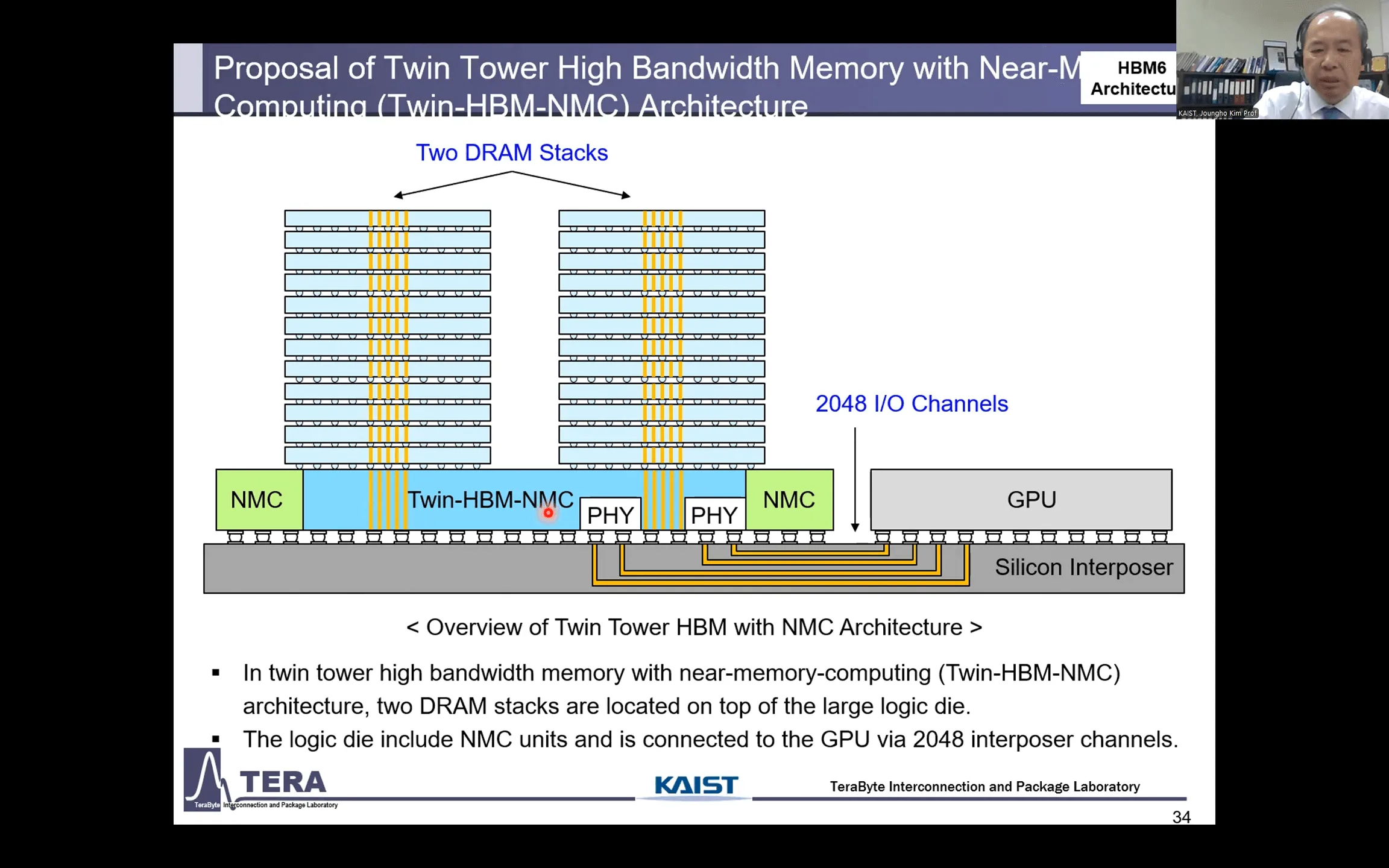
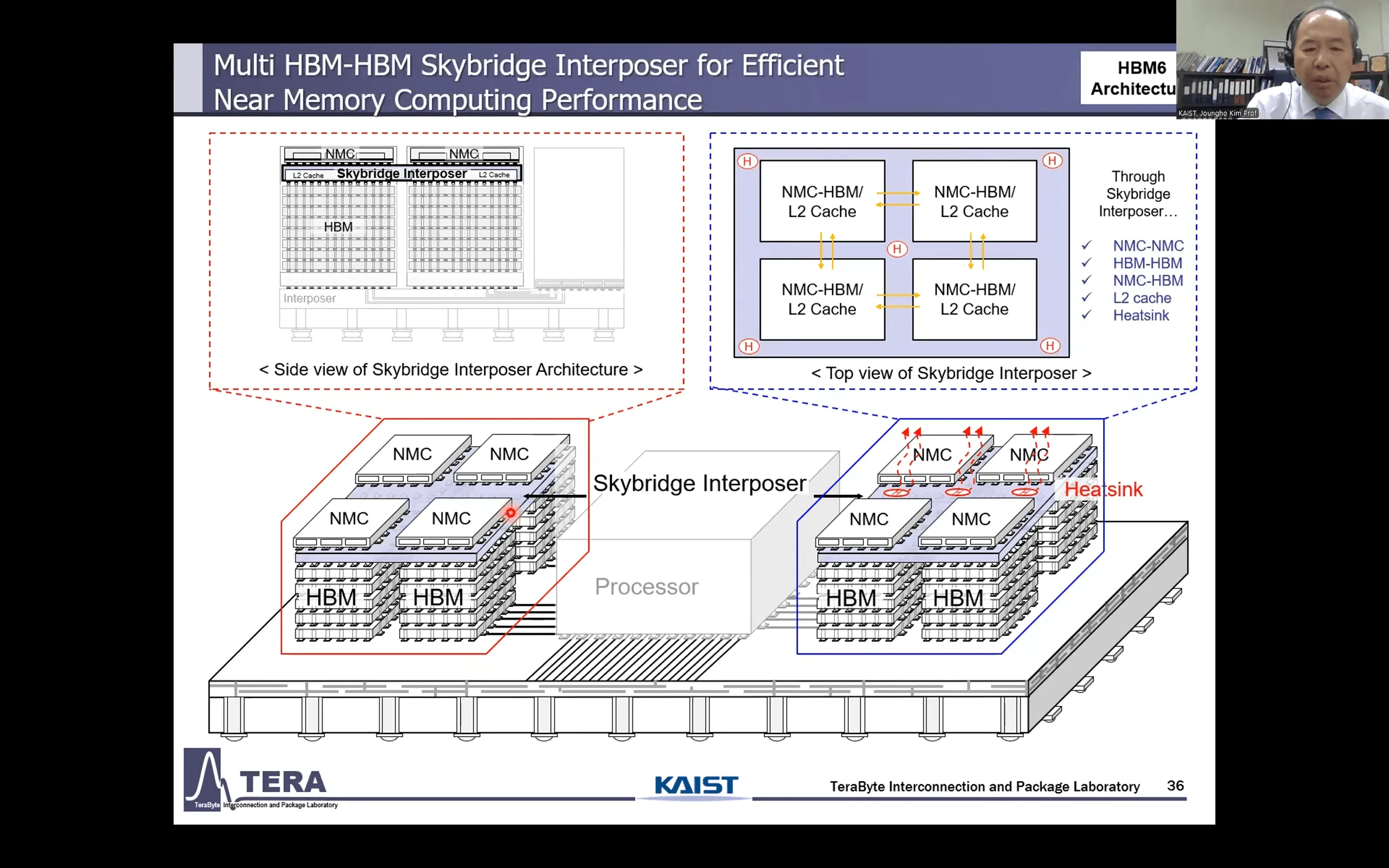
もう一つが「ガラスインターポーザ」の導入である。シリコンよりも大きなサイズで製造でき、反り(ワープ)が少なく、信号損失も低いガラスをインターポーザに採用することで、超大規模なAIチップの製造を可能にする。この世代から、HBMの性能はDRAMプロセスだけでなく、それをどう実装するかというパッケージング技術によって定義される時代へと完全に移行する。
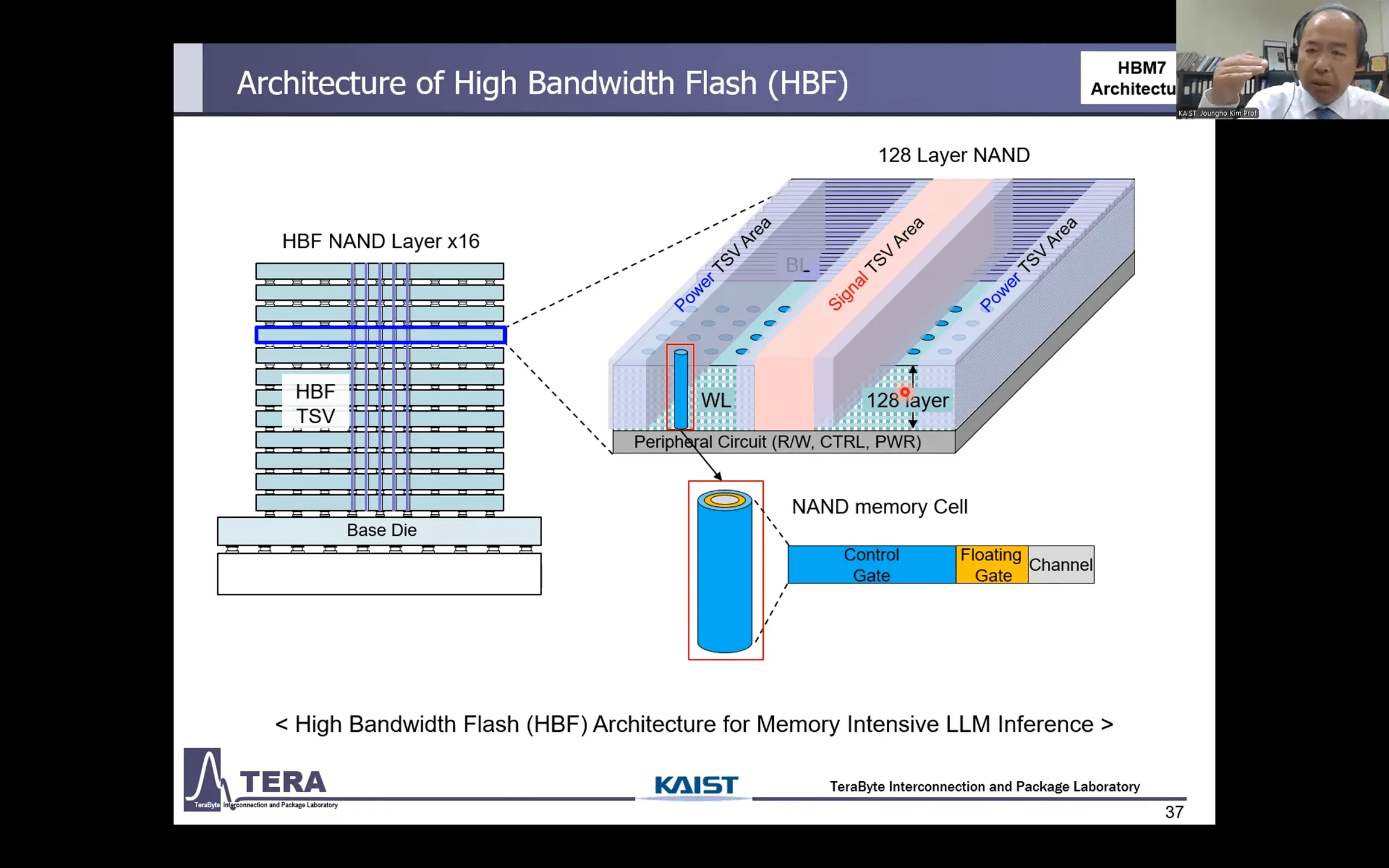
HBM7 (〜2035年):メモリ階層の支配者へ、異種メモリ統合と埋め込み型冷却
HBM7は、単一のメモリ技術の枠を超え、多様なメモリを統合・管理する「メモリ階層の支配者」へと進化を遂げる。
- データレート: 24 Gbps
- I/O数: 8192-bit
- 帯域幅/スタック: 24.0 TB/s
- 容量/スタック: 160GB (20-Hi) / 192GB (24-Hi)
- 冷却: 埋め込み型冷却(Embedded Cooling)
- アーキテクチャ: ハイブリッドHBM(HBM-HBF, HBM-LPDDR)
この世代の最大の特徴は「HBF(High-Bandwidth Flash)」との統合だ。HBMの隣に、NANDフラッシュをベースにした大容量(テラバイト級)かつ高速なHBFを積層することで、特にAI推論で必要とされる巨大モデルを単一パッケージ内に保持することが可能になる。さらに、低消費電力の「LPDDR」メモリも統合され、HBMのベースダイがこれらの異種メモリ全体を管理する「メモリマネジメントロジック」を搭載する。
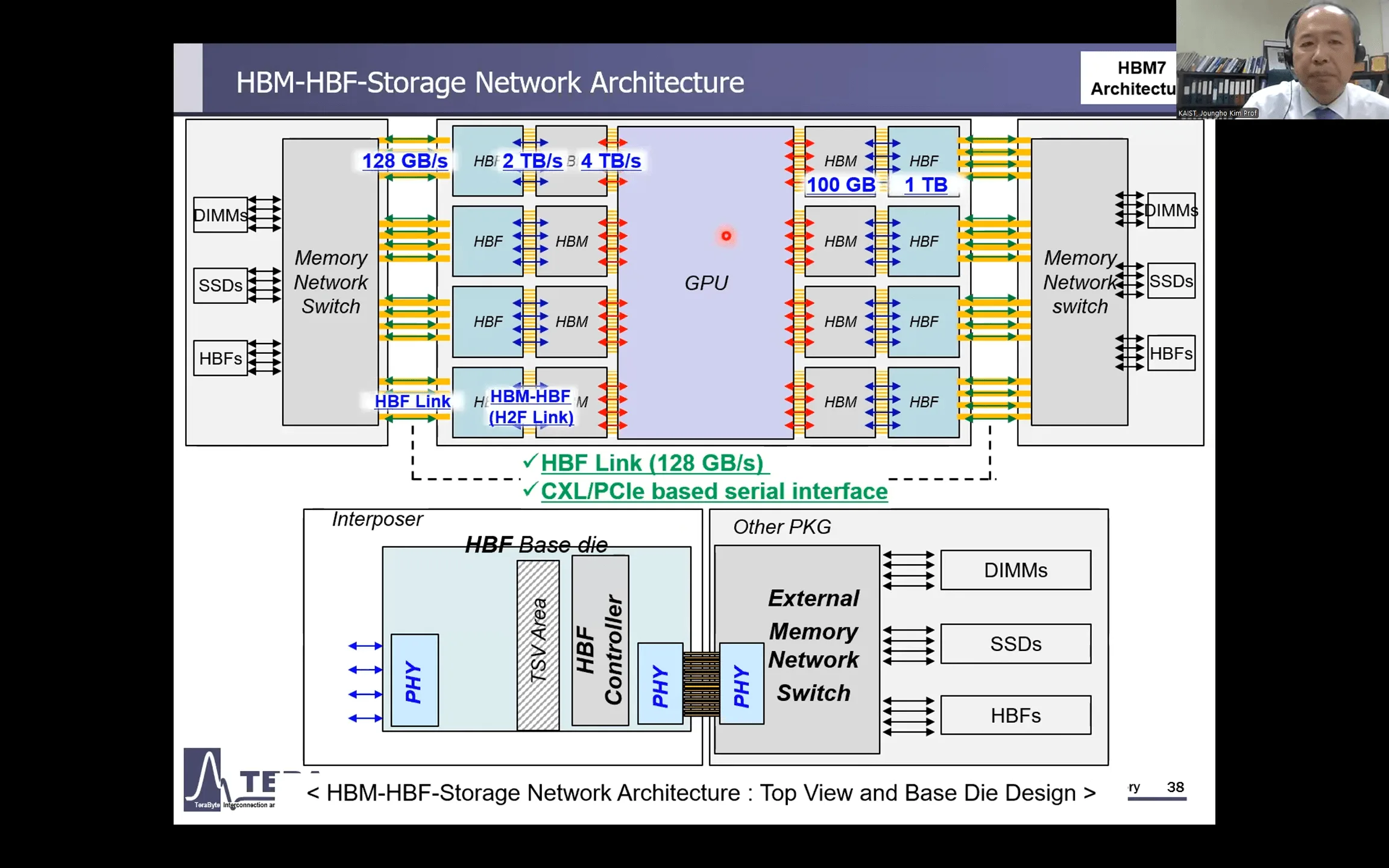
そして冷却技術は、チップ内部に直接冷却液の流路を設ける「埋め込み型冷却」という究極の領域に踏み込む。これにより、積層構造の内部にこもる熱を効率的に排出し、性能の限界をさらに押し上げる。
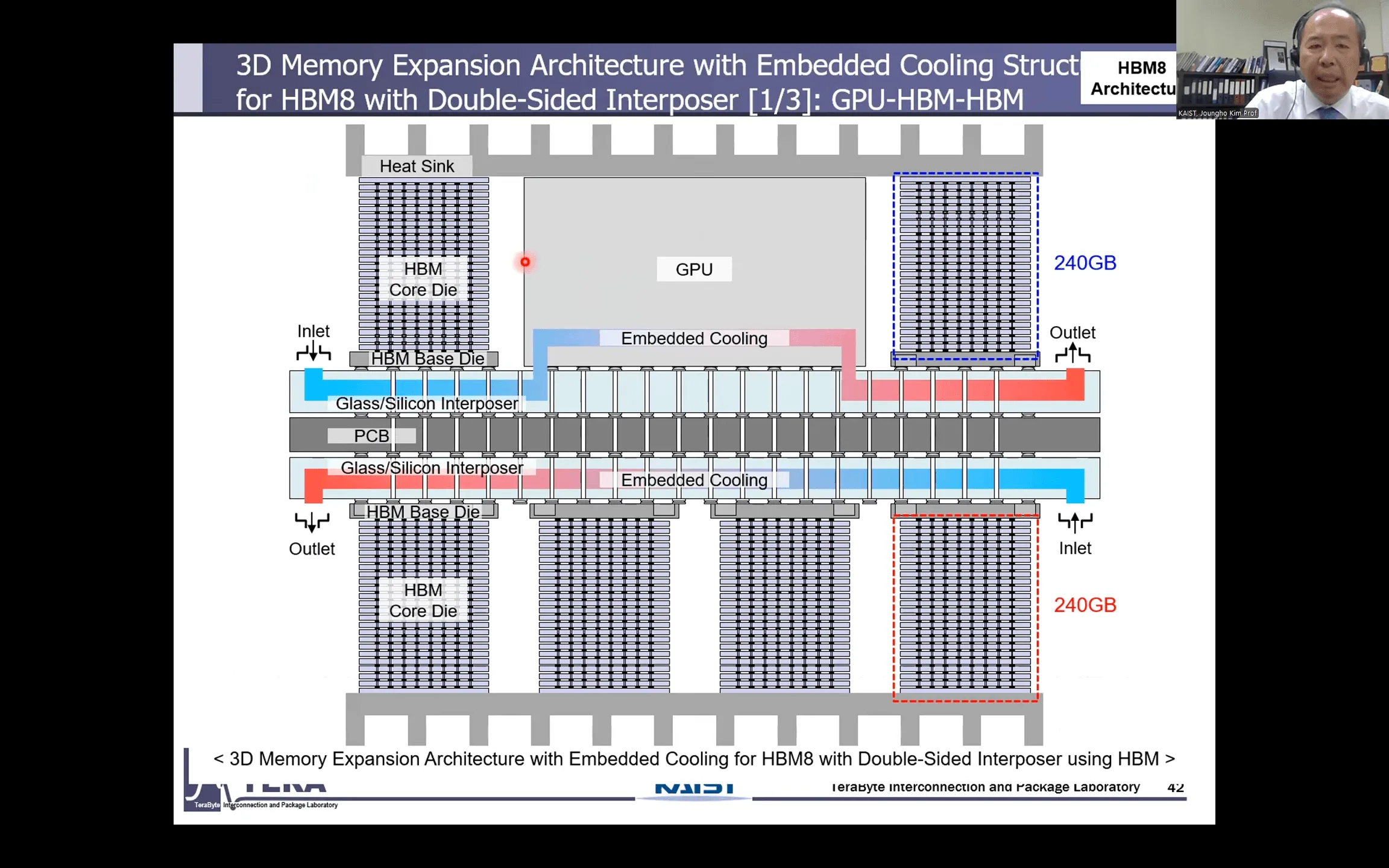
HBM8と未来 (〜2040年):「HBMセントリックコンピューティング」が描く新世界
HBM8は、これまでのコンピューティングの常識を覆す、真のパラダイムシフトを予感させる。
- データレート: 32 Gbps
- I/O数: 16384-bit
- 帯域幅/スタック: 64.0 TB/s
- 容量/スタック: 200GB (20-Hi) / 240GB (24-Hi)
- アーキテクチャ: 完全3D GPU-HBM統合、HBMセントリックコンピューティング
- インターコネクト: Coaxial TSV, 光通信
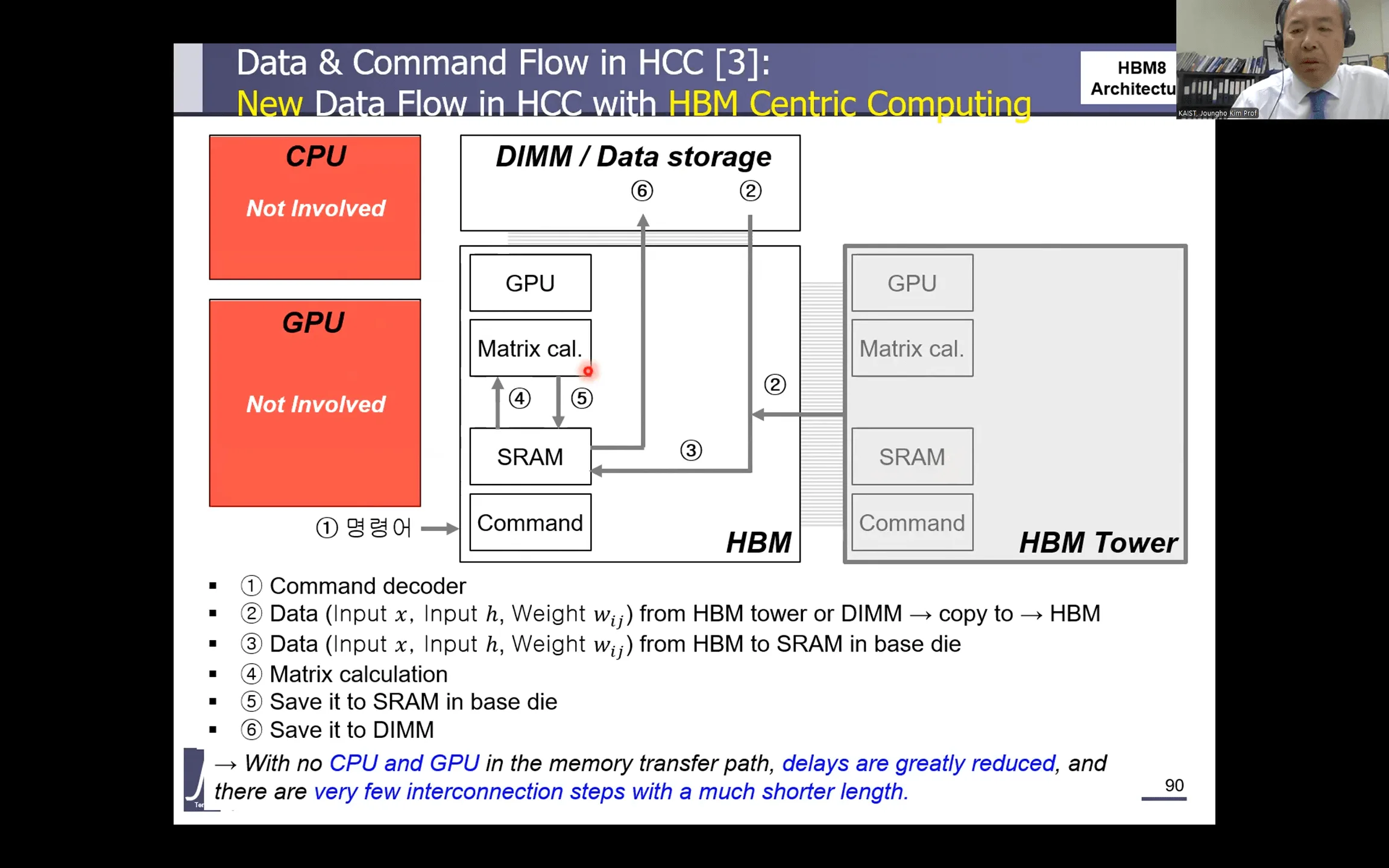
HBM8が目指すのは「HBMセントリックコンピューティング」というビジョンだ。これは、CPUやGPUが演算の中心である従来のフォン・ノイマン型アーキテクチャから脱却し、HBM自体がデータの管理と演算の中心となる世界である。HBMがGPUの機能を包含し、データが発生する場所で直接計算を行うことで、ボトルネックという概念そのものを消滅させることを狙う。
実装技術も異次元の領域に入る。パッケージの両面にHBMやGPUを実装する「両面インターポーザ」、超高速信号をノイズなく伝送する「同軸TSV」、そして電気信号の限界を超える「光通信」の導入が検討されており、HBMはAI時代のコンピューティングの心臓部として完全に君臨することになるだろう。
進化を支える舞台裏の革命:「AIによる設計」
この驚異的なロードマップの実現には、もう一つの革命が不可欠である。それは「AIによる設計革命」だ。HBMの設計は、信号の品質、電力供給の安定性、熱の管理など、無数の要素が複雑に絡み合い、もはや人間の能力だけで最適解を見つけることは不可能に近い。
KAISTなどの研究機関では、電力供給網の最適化、TSVの最適配置、冷却システムの設計などにAIエージェントを導入する研究が活発に進められている。強化学習や生成AI、大規模言語モデル(LLM)を活用し、設計サイクルを劇的に短縮し、性能を最大化する。HBMの開発競争は、それを生み出す「AIを使いこなす能力」の競争でもあるのだ。
このロードマップが示す未来は、単なる半導体の一技術の進化ではない。それは、計算のあり方そのものを根底から覆し、AIの能力を無限に解放する可能性を秘めている。HBMはメモリという枠を飛び出し、AI時代の新たなスケーリング法則を牽引するエンジンとなる。この巨大な地殻変動の中で、どの企業が、そしてどの国が主導権を握るのか。HBMを巡る技術開発競争から、我々は一瞬たりとも目が離せない。
Sources


